
Hi,
I have a problem extracting data from my text file.
The file looks like this:
******************************************
#Textlimiter=;
#Decimalsign=.
#Provadm
Column1, Column2...ColumnX;
"Value1";"Value2"...""ValueX";
"Value3";""Value4"..."ValueY";
#Provdat
ColumnA, ColumnB...ColumnZ;
"ValueXX","ValueYY"..."Value11";
"ValueQQ","ValueRR"..."Value22";
#End
******************************
The ProvAdm-section can contain one or more rows
The ProvDat section can also conrtain one or more rows
I want to read ProvAdm section into one table (SQL Server) and ProvDat into one table (SQL Server) but I dont reaaly understand how to find out where ProvAdm section ends (how many rows should be read) or where ProvData starts (where should I start reading)
An additional dimension to the problem is that I need to read multiple files at one go...
Perhaps my explanation is not complete but please ask and I will try to explain a little more 🙂
//Magnus
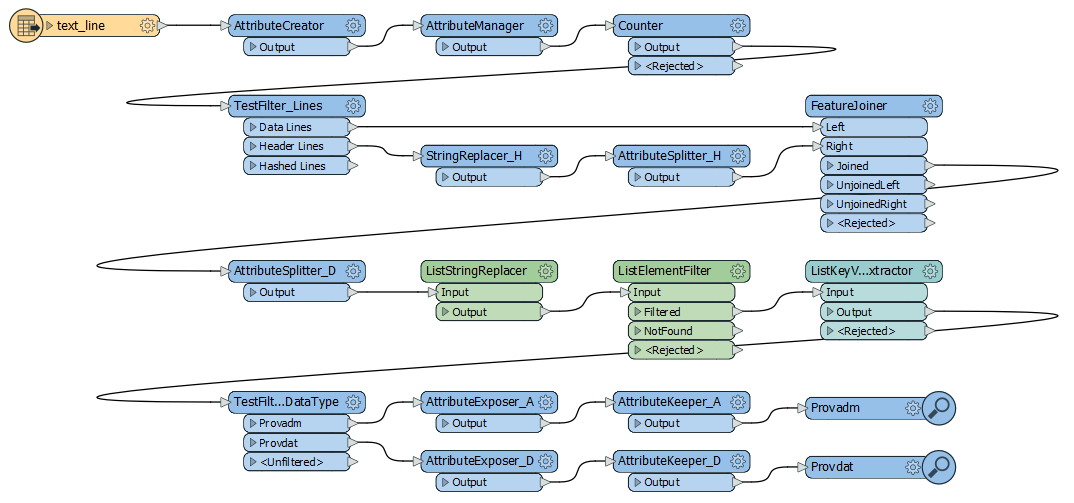


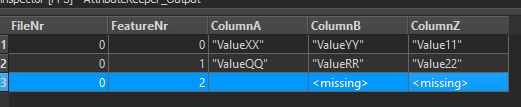 Probably not the most elegant solution but it works. You will have to create the Pravadm part yourself but you can reuse some of the transformers used for the Provdat datastream.
Probably not the most elegant solution but it works. You will have to create the Pravadm part yourself but you can reuse some of the transformers used for the Provdat datastream.
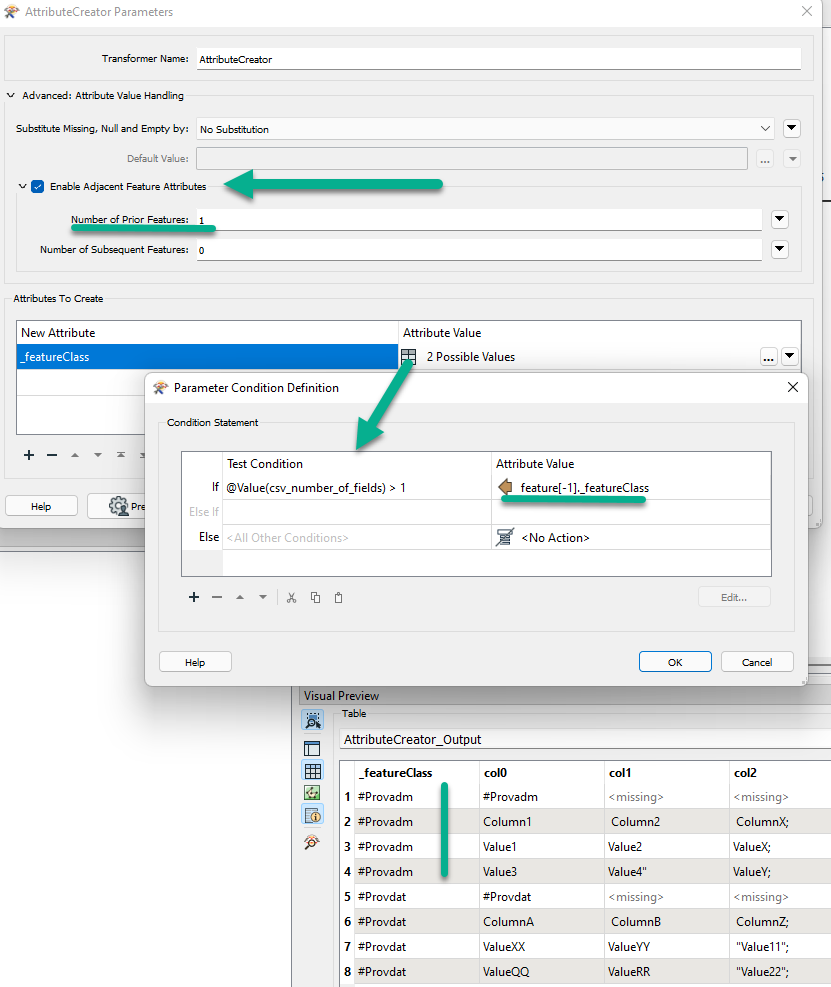 I've attached an example workspace (FME 2021.2) based on the sample data created by
I've attached an example workspace (FME 2021.2) based on the sample data created by 

