



Hello everyone,
This might be a simple question, but for some reason I can't figure out how to remove rows with only Null Values (Of course I can useTestFiler or Tester, but would be cumbersome work, since I have a lot of columns and I don't want to go into that rabbit hole)
These rows with Null values came into existence, since I read in an excel file with two worksheets with two different schemas. So the column names in worksheet 1, is different compared to the column names in worksheet 2.
Therefore all the values from worksheet 2 have null values. I actually don't need worksheet 2, so I was thinking there might be 2 solutions.
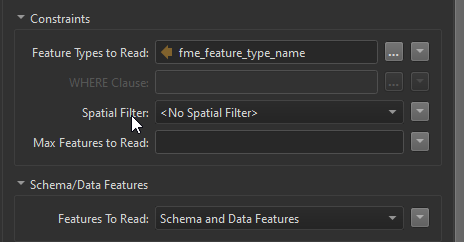
1) don't read in worksheet 2 or
2) remove the null values
For both of them I don't know the answer.....dramatic sound effects..
So if someone knows the answer, that would be very nice.




")

")





