Hi folks,
I started using the Tygron API, which I used to extract building information for a specific location/site. However, when I request the building information, the response body is a JSON Array with JSON Objects of which only approximately 1/3 of the JSON Objects are actually about buildings. To determine if a JSON Object is about a building, I'm checking if it contains a "BAG_ID" attribute.
Below is some a sample_json Array that illustrates the data structure I'm working with:
[
{
"id": 1,
"name": null,
"attributes": {
"type": "Bridge"
}
},
{
"id": 2,
"name": "just a shed",
"attributes": {
"type": "Shed"
}
},
{
"id": 3,
"name": "just a house",
"attributes": {
"type": "Building",
"BAG_ID": 1.5010000000035E14
}
}
]In the real world data, the JSON Array contains a lot more features and data.
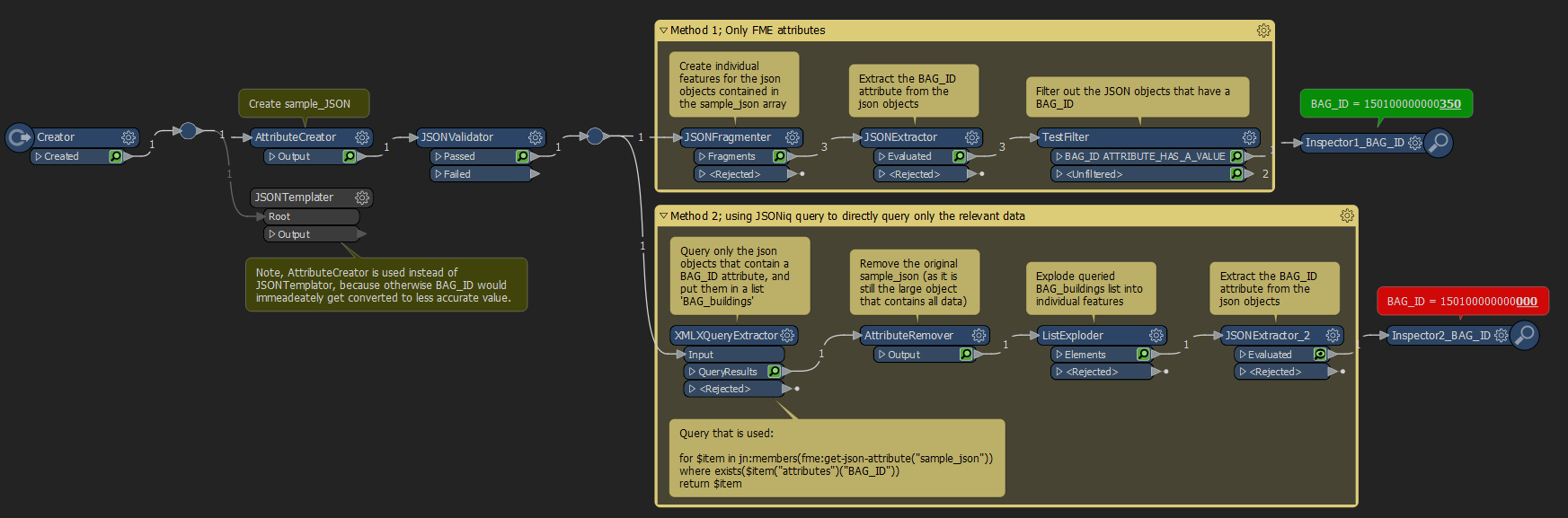
Initially I queried out the JSON Objects on buildings using the following steps;
JSONFragmenter (create features for individual JSON Objects),
JSONExtractor (Extract BAG_ID attribute)
TestFilter (Extract features where the BAG_ID attribute exists (has a value))
Now this method works just fine, but I thought that a direct query on the data (using JSONiq) would probably be more efficient. When I try this on the real data, this indeed seems to be more efficient (i.e. quicker).
In this construction I'm using a XMLXQueryExtractor transformer with the following query to store the desired features in a list:
for $item in jn:members(fme:get-json-attribute("sample_json"))
where exists($item("attributes")("BAG_ID"))
return $itemthen I'm using an AttributeRemover to remove the original sample_json (which contains all the features and is quite large)
Then I'm using a ListExploder to create individual features for the JSON Objects that I queried out in the previous step (note, I want to use the default setting to merge incoming attributes at the ListExploder, and without the previous AttributeRemover the whole original JSON Array would get exploded onto each list element/feature).
Conceptually this method works well for me (most importantly it seems to be quicker), but I'm encountering one issue. When using this JSONiq query method, the value for the BAG_ID gets 'truncated' in some sense. Instead of the original value of '1.5010000000035E14', the value gets truncated to '1.501E14'. Since this BAG_ID attribute is also a key on which I need to join/merge data later on, this unfortunately makes the more efficient JSONiq query not useable in the end.
Is there any way to use the more efficient JSONiq query method, without the BAG_ID getting truncated?
Any ideas are greatly appreciated.
Kind regards,
Thijs
See below screenshot for an overview of this workspace. I also added the workspace itself to this case.