")

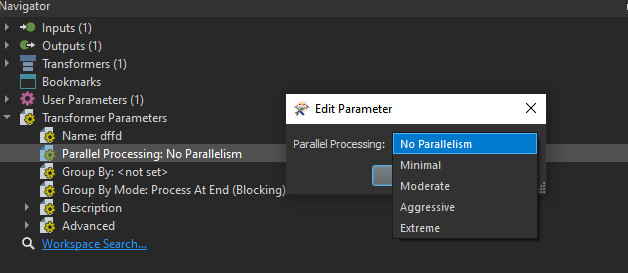
I've got a very big feature class which contains more than 12,000,000 polygons and I need to use TopologyBuilder and other transformers to do some processing, but it took too much time for TopologyBuilder to process the dataset. So I came up an idea that I split the dataset into several some small feature classes which contain less polygons. Now I only need to run my workspace repeatly through WorkSpaceRunner, but WorkSpaceRunner seems can not process feature classes in the GDB one by one, I have to export feature classes in to separate GDBs to get it work, but exporting processing also took a lot of time and made my folder very complex.
So is there any way to iterate through GDB? I'd appreciate any @suggestion, thank you!

")