Hi.
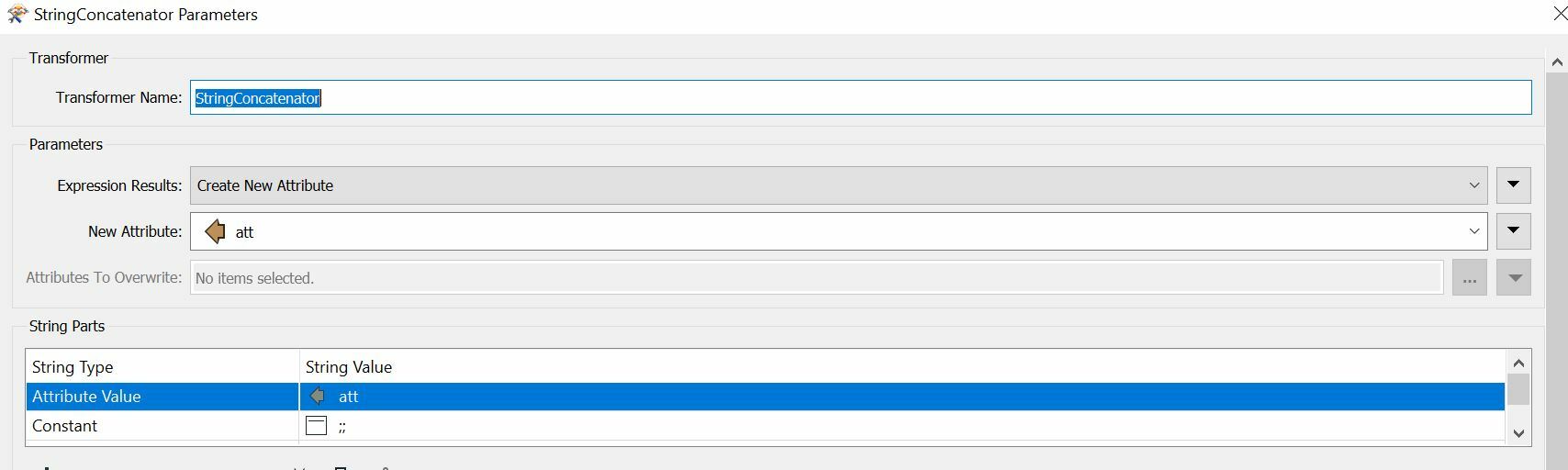
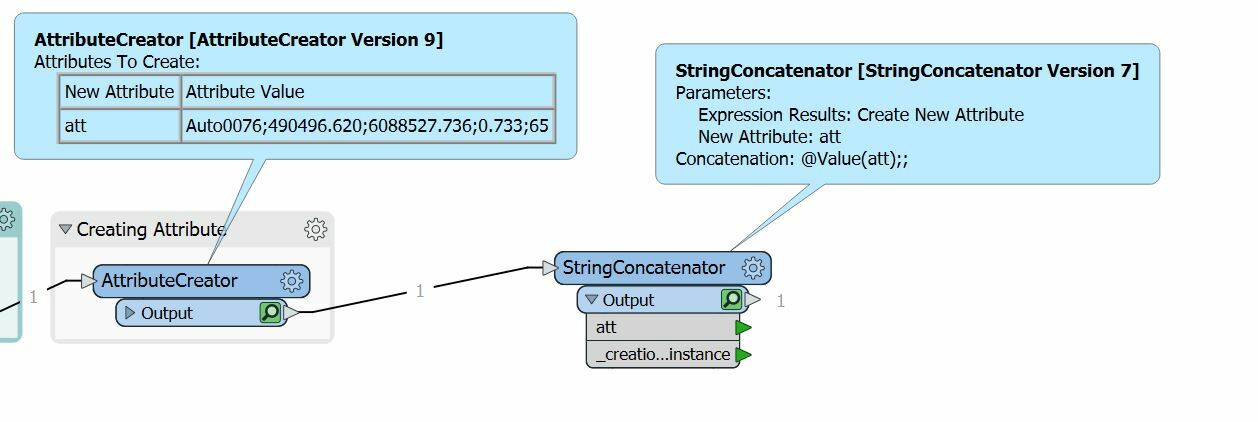
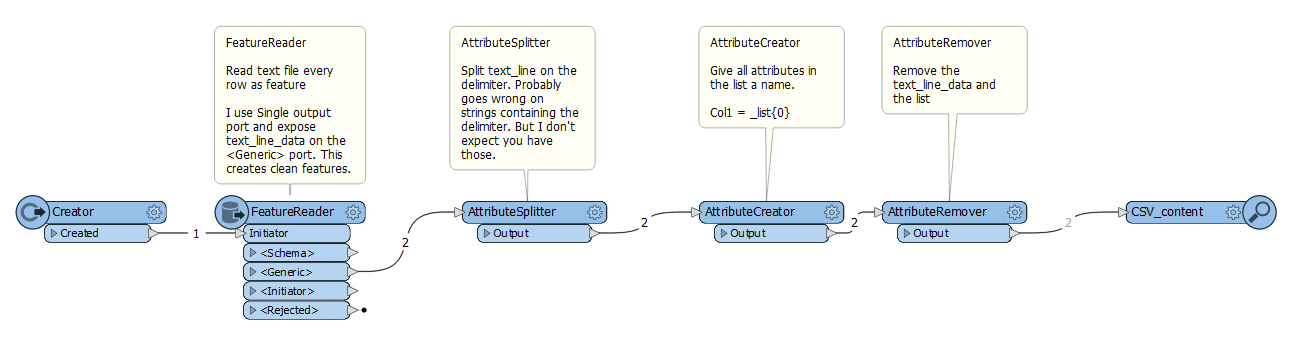
I am trying to create a workbench that transforms a certain csv file into one that my drawing program can understand. It uses semikolons as delimiters, but it also needs every row to have two semikolons in a certain place.
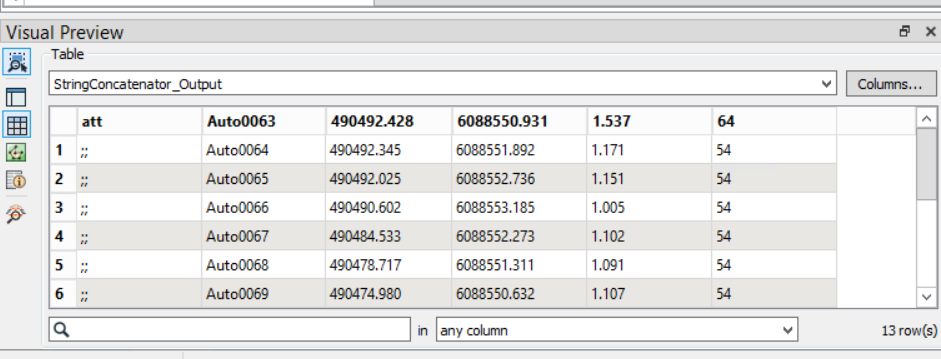
This is an example of how it should be:
Auto0076;490496.620;6088527.736;0.733;65;;
This is an example of what I can make it write: Auto0076;490496.620;6088527.736;0.733;65
How can I insert the extra two semikolons at the end?
Regards Rasmus