Dear FME community,
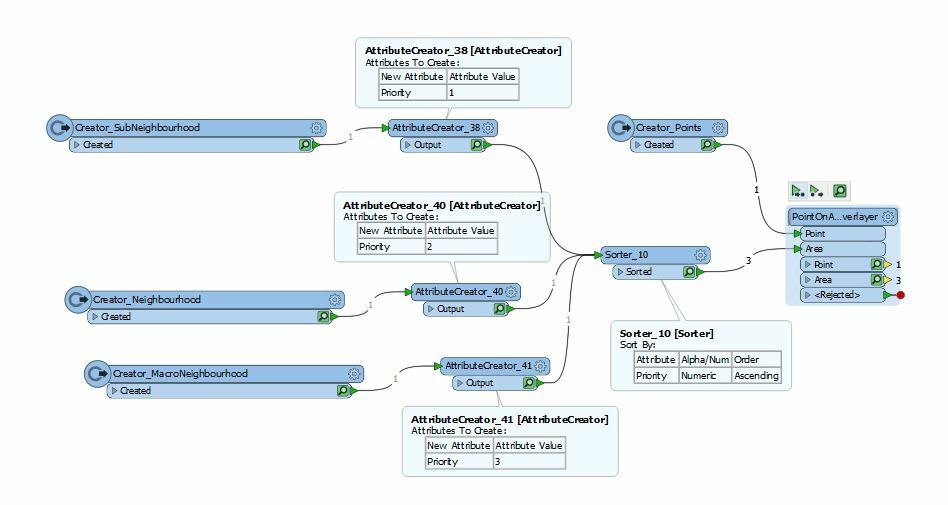
I have a CSV file containing points (longitude and latitude for properties) and a neighborhood shape file containing nested polygons. There are three types of the polygons from the smallest to the largest: Sub-neighborhood, Neighborhood and Macro-neighborhood.
I would like to join the points to the polygons and append only one polygon ID to each property. If a property falls within multiple nested polygons, I would like to get the ID from the smallest polygon. For example, if a property is in a Sub-neighborhood which is nested in a Neighborhood, the Sub-neighborhood ID should be appended to the CSV file.
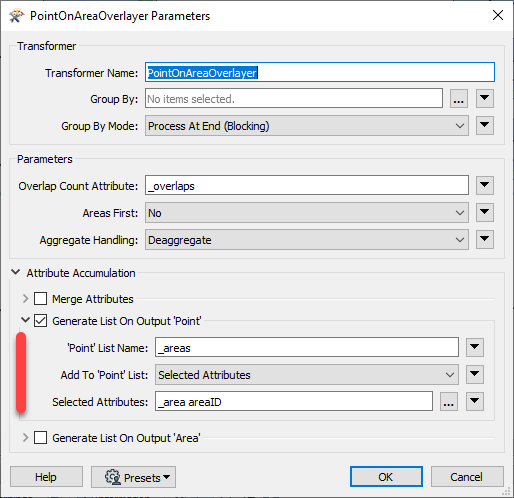
Currently, I am using the PointOnAreaOverlayer, and I always get the IDs from the largest polygons when there are multiple polygons matched.
Which transformers should I use to always get the IDs from the smallest polygons (based on the polygon type) when there are multiple polygons matched?
I appreciate your help.
Thao