
I am trying to export data from SQL to CMDM Geodatabase. 200 values got truncated. I changed some of the attribute widths in CMDM, and truncated values decreased to 4. Instead of trying to check each attribute manually, is there any way to find these values directly?

Solved
How to find truncated values

 +6
+6- Contributor
Best answer by gio
@canerakin111
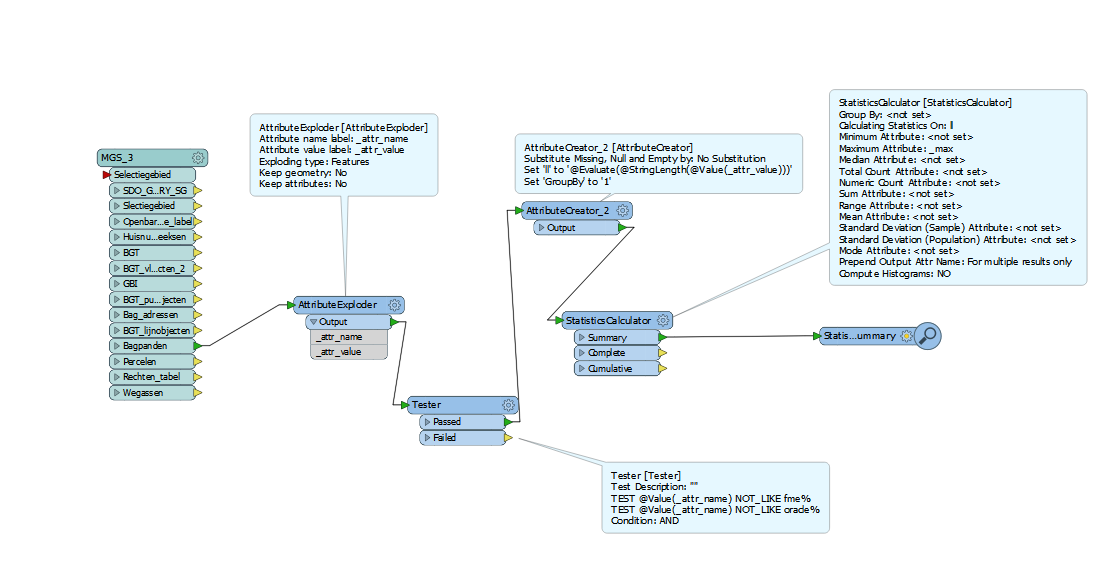
If you want to know longest attribute value of a set of attributes.
Attribute Exploder (default setting) followed by a attribute creator using the arithmetic editor :
New Attribute = @StringLength(@Value(_attr_value))
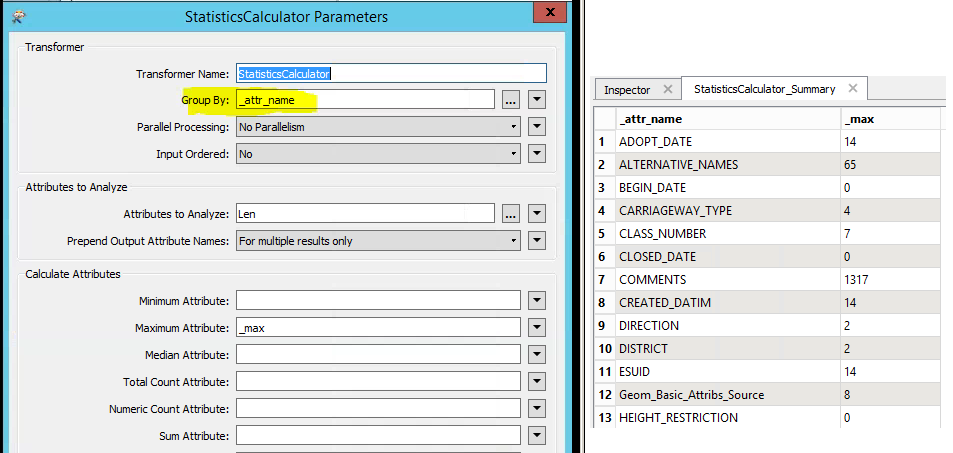
Then StatisticsCalculator max on that value (no group by attribute required).
If you only require this max you can use Summary output from the
Statistics Calculator
.This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.











Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.