I have spent hours re-engineering my data but couldn’t find a best resolve to automate data to provide statistics. Thinking, I could have saved myself a lot of trouble with a simple transformer with set logic using FME.
I have a range of attributes containing values such as "Class1, Class1a, Class3, Class4a". values are picked up from a drop down list by the surveyors, that sits in an attributed separated by comma (,).
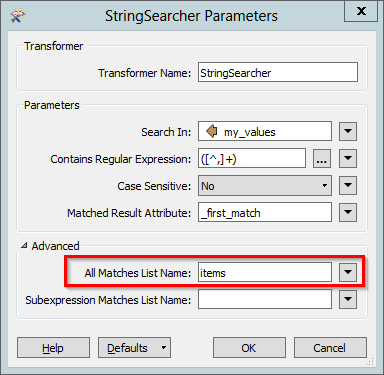
I need to count the number of items in each attribute, assuming that they were separated by commas. So, the transformer would need to return the value 4 for my example above and for various other attributes using the same logic.
I need to use the logic "If the cell is blank, value= 0, if the cell is not blank, but does not contain a comma, value=1, otherwise, value= (number of commas +1) i.e. read the string, if there are two commas in the string, then there must be three values, and so on.
Logic is clear of what I'm trying to achieve but, I'm struggling on the bit that counts the number of commas found in the string.
Anyone got an idea how and which FME transformers can be applied ?
All help will be gratefully appreciated.