Hi FME ninjas,
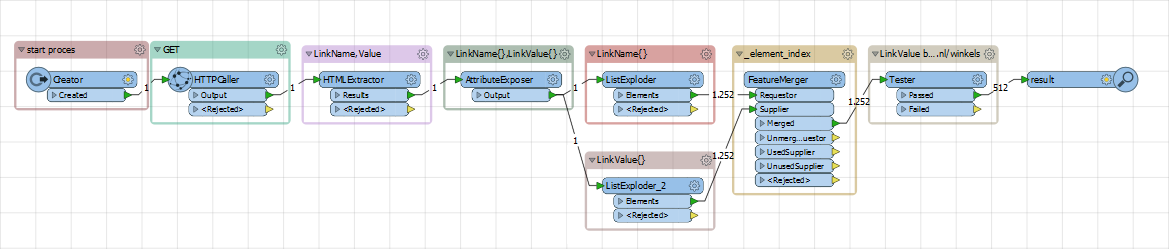
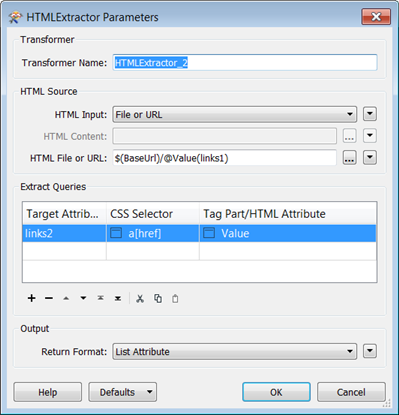
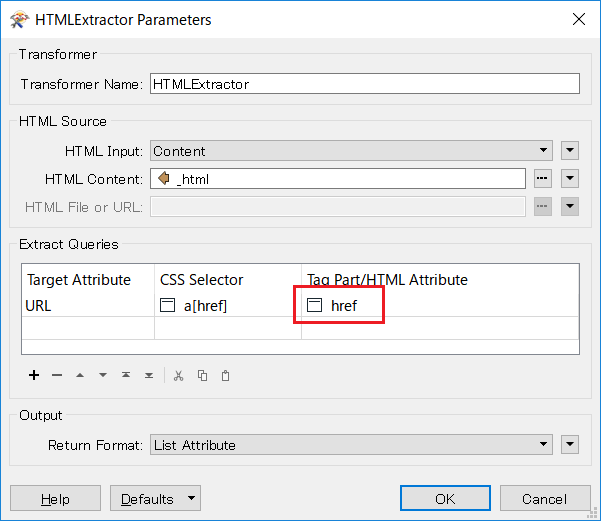
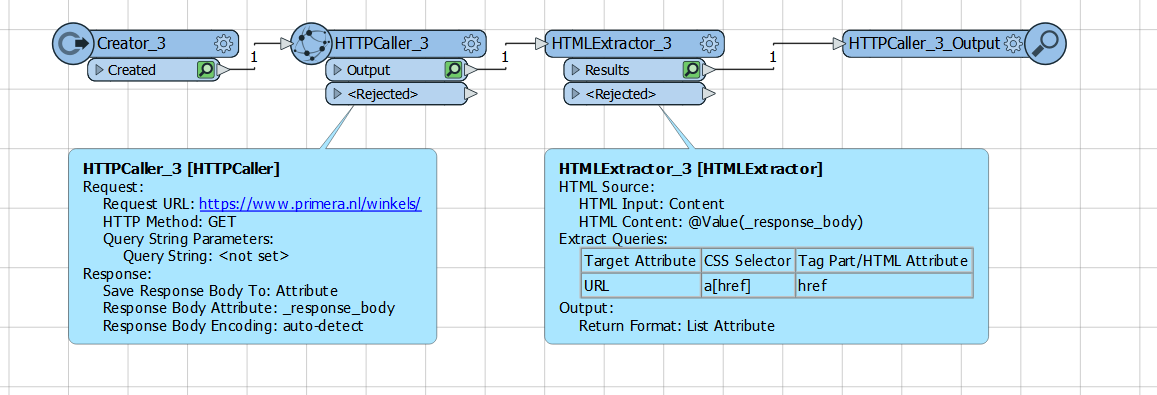
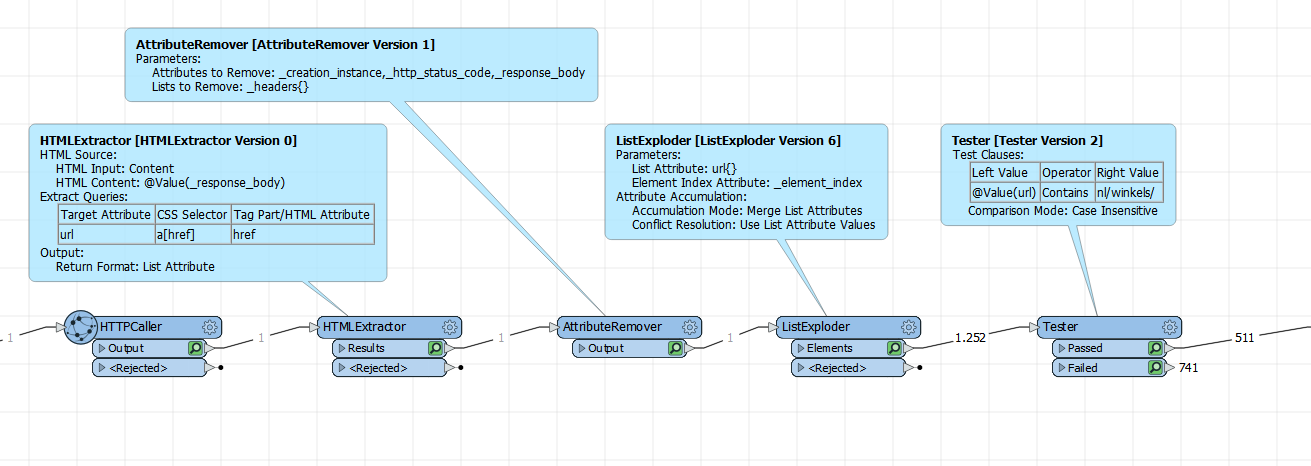
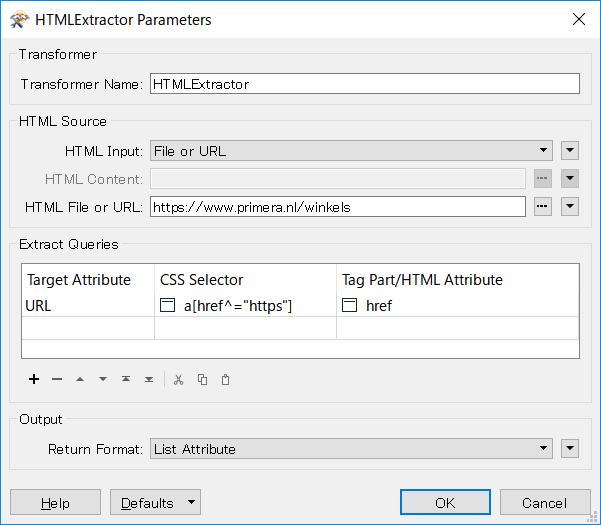
I'm using the HTTPCaller to call a website containing multiple URLs in its HTML.
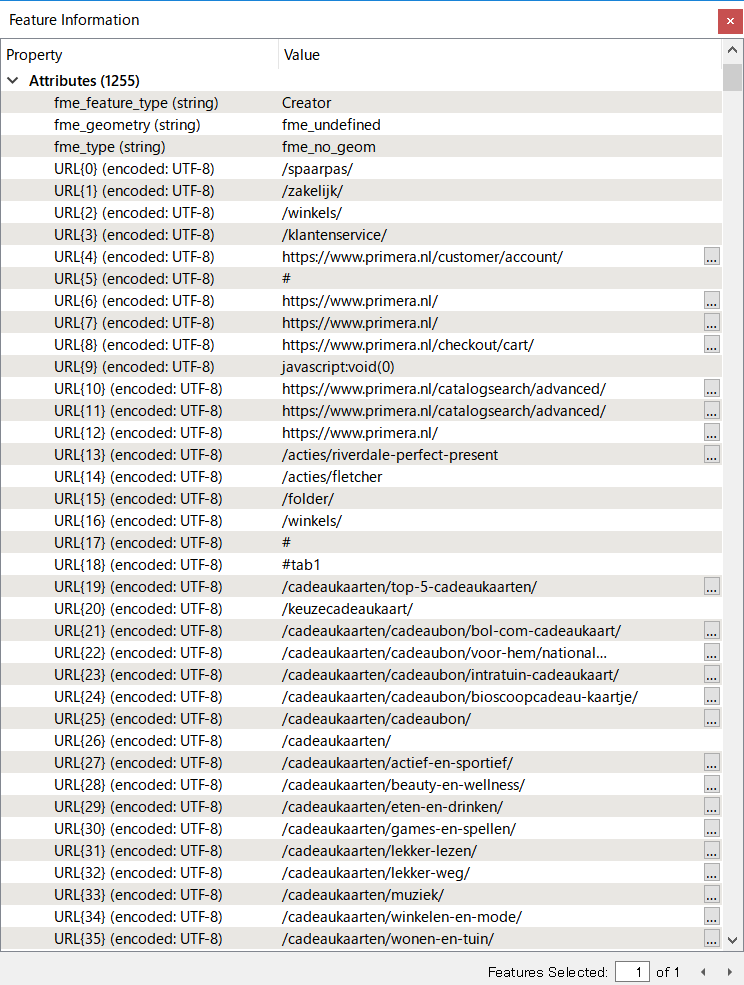
I'm trying to extract all the URLs that have below format, based on these I'd like to create and attribute (URL) that shows all unique urls as features.
What I have: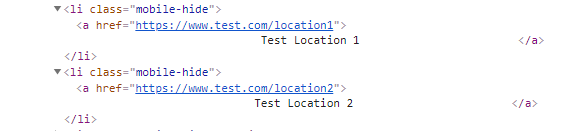
What I want:
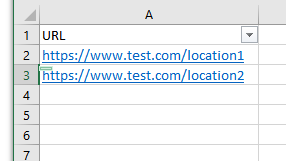
Does this make any sense ;-) ?
Thanks,
Eduard