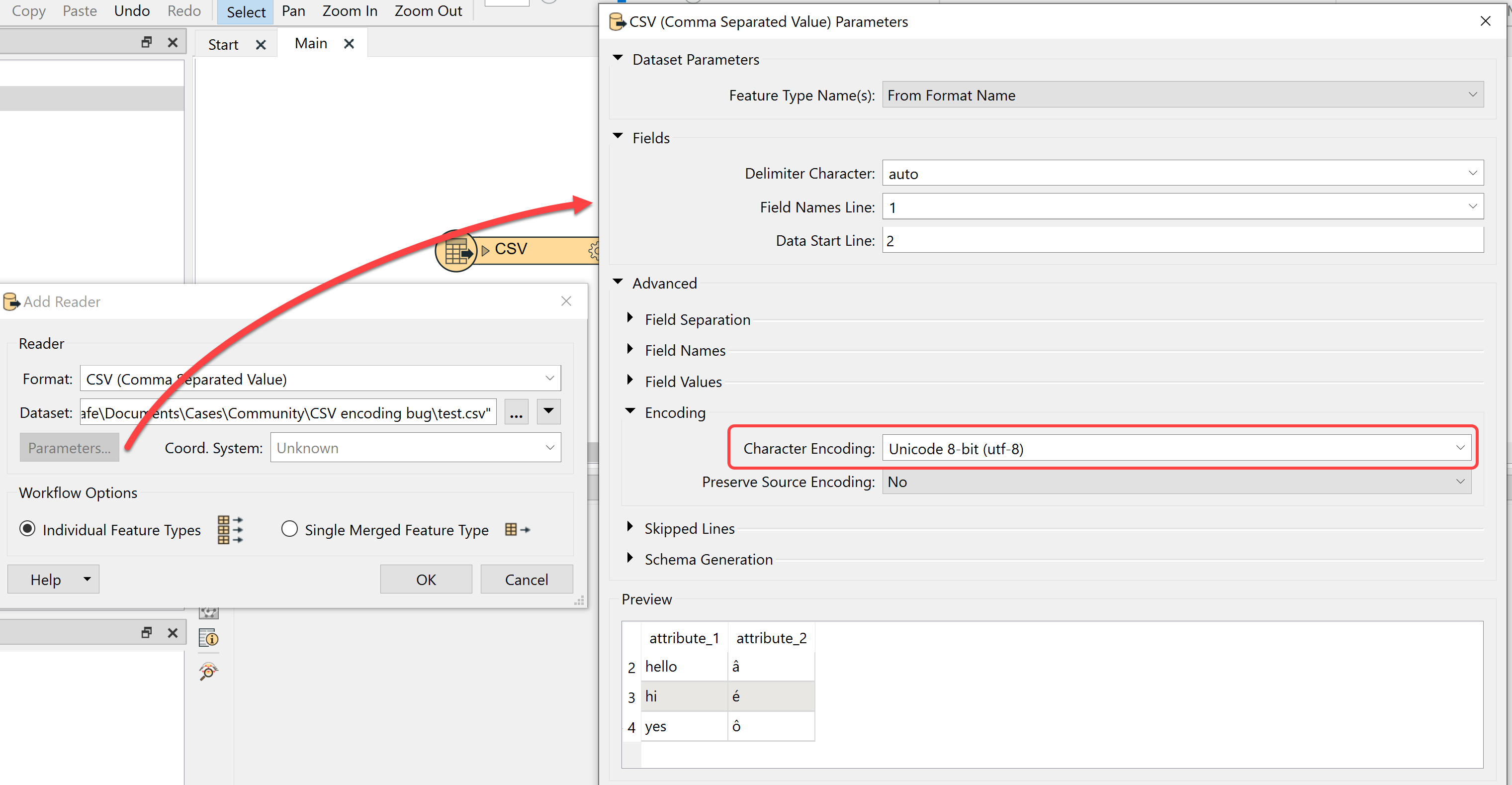
Bulk copy failed on table 'tv.vagnat_framtida' using delimiter ':'. Error was 'ERROR: invalid byte sequence for encoding "UTF8": 0xc3 0x3a
CONTEXT: COPY vagnat_framtida, line 33This error kept me busy for some hours exploring character encoding in shapefiles, FME and PostGIS. Which did not help. Not until I did some data digging and found the error.
The data in a shapefile apparently comes from a qualified geodata store, and some long text fields have been truncated in the conversion to shape, leaving what appears to be incomplete character codes. And this causes PostGIS problems. The error message comes from deep within PostGIS.
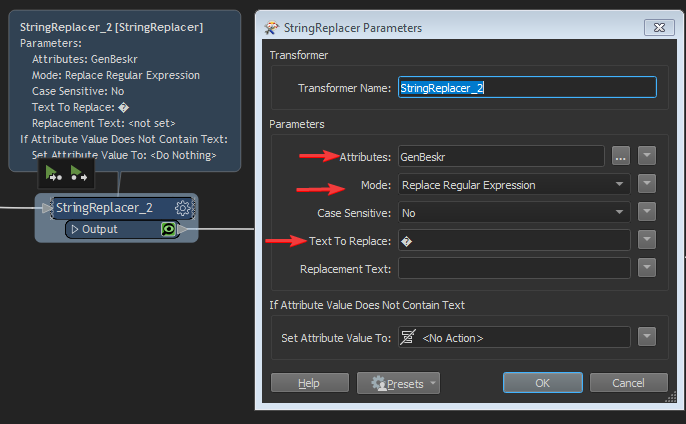
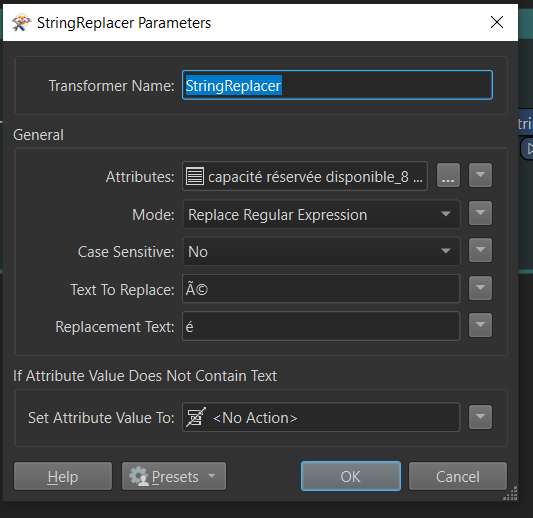
I have tried to cut a few bytes from the string with SubstringExtractor, but then the whole string became HEX. Very strange. Since it is invalid data, there seems to be no way of catching these characters with any of the FME string tools. And the error appears only in the Postgis writer, not before so it cannot be logged.
Basically, I am looking for suggestions on how to catch and clean the strings from false bytes. I do not mind truncating the string further, since an unknown part already is lost. I will enclose a zipped shapefile for your perusal. See field GenBeskr, line 33 and possibly elsewhere as well.



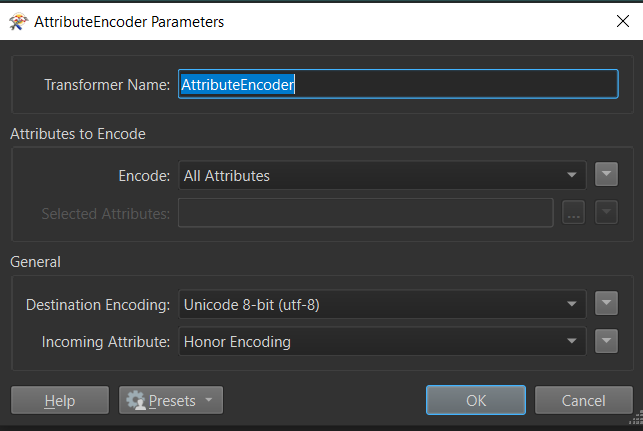
 My BD has UTF-8 encoding, Collation and Character type in English_United States.1252.
My BD has UTF-8 encoding, Collation and Character type in English_United States.1252.