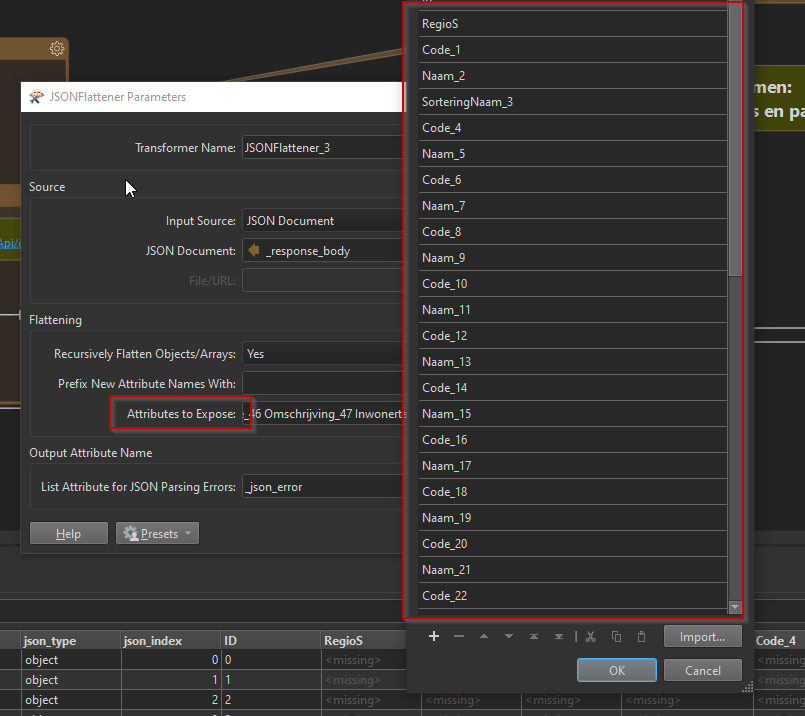
I have a HttpCaller that reads different kinds of information depending on the user input and therefore the attribute column names are all the time different. With the JSONFlattener you can import the column names that you want to expose, but ideally I would like to expose them dynamically. I was wondering if something like that is possible.