The problem:
I have two lists which are related to each other by way of index so lets say we have the following format -
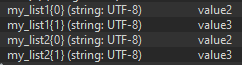
List 1 (contains 4 Elements)
List 2 (contains 4 Elements)
The Elements in each list relate to one another so Element 0 in List 1 is directly relatable to Element 0 in List 2. Element 1 in List 1 is directly relatable to Element 1 in List 2 and so on and so forth for the rest of the Elements.
What I'd like to Achieve:
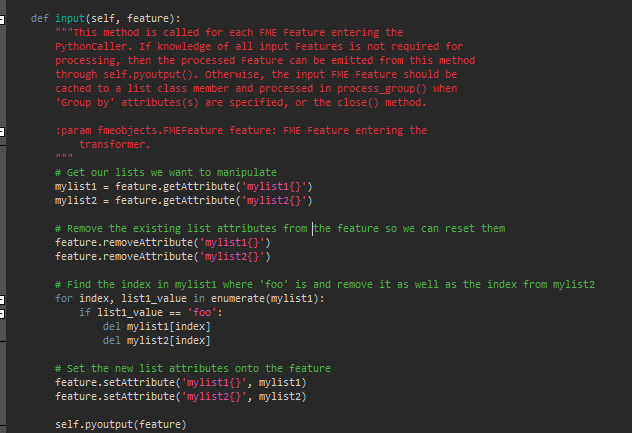
If any Element stored in List 1 = "foo" -- I would like to remove it as well as the related Element in List 2. I think this is easily achieved if it is possible to extract not just the attribute of the Element in the lists, but the Element Index as well. How do I do this?
I am able to extract the attribute name of each Element easily by using:
my_list = feature.getAttribute('my_list{})
Thanks in Advance.