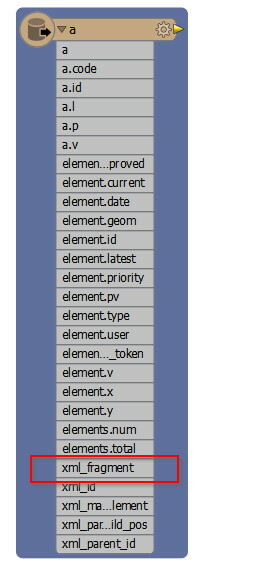
<?xml version="1.0" encoding="UTF-8"?> <elements total="877" num="877"> <element id="242698" v="2" pv="1" x="1109133" y="6970266" geom="POINT (9.9699121998145532 52.9278245931941953)" priority="0" type="99" approved="1" current="1" latest="1" date="2014-07-08 13:15:52" user="10" user_token="Friedrich"> <types> <type id="562"/> </types> <periods> <period id="32"/> </periods> <events> <event type="1" begin_prefix="~" begin_year="1790" end_prefix="~" end_year="1790"/> </events> <aspects> <a id="1" l="de" v="Alter Schafstall"/> <a id="2" p="5" code="6"/> <a id="3" p="10" code="3"/> <a id="39" l="de" v="Zehn "/> <a id="41" l="de" v="Zwischen"/> <a id="57" l="de" v="etwa 40m"/> </aspects> <relations/> <media> <medium id="79236"/> <medium id="79237"/> </media> </element> </elements>It party works when I define the "elements to match" as <element> but the attributes in the <a> tag are not being flattened. They get translated into the "xml_fragments" field which contains xml-style code. I don´t understand where this "xml_fragments" comes from and would like simply map the attributes into their own fields like "a.id" "a.l" or "a.v".
Could anyone explain to me what is going on here?