I have run a hadoop job and set multiple reducers in the reduce phase, then I have customize a counter to sum the results of multiple reducers. However, the data type of the result in each reducer is double, while the increment method of conuter only supports the long data type. If the conversion from double to long is forced, the precision will be lost. How can I solve this problem?

Question
Hadoop Customed counter

")

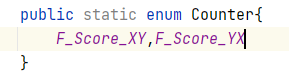 the source code of the increment method of the counter is as follow:
the source code of the increment method of the counter is as follow: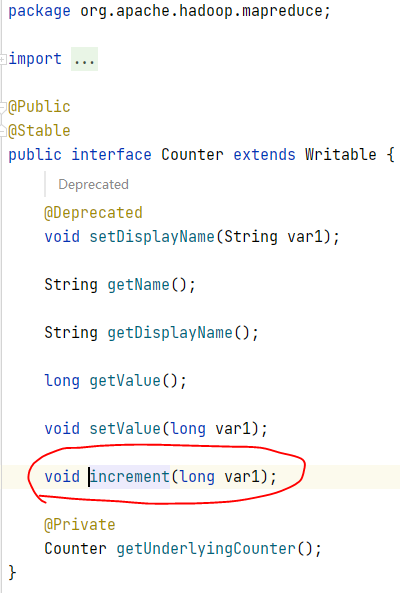 the part code in the reduce phase is as the figure depicts. The 'f' is a double num, so needs to call Math.round to convert double to long,which causes the loss of accuracy.
the part code in the reduce phase is as the figure depicts. The 'f' is a double num, so needs to call Math.round to convert double to long,which causes the loss of accuracy.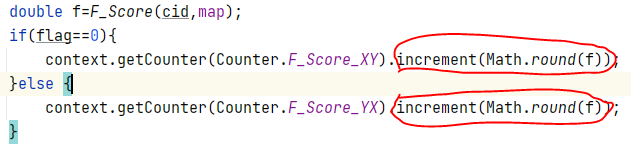
Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.