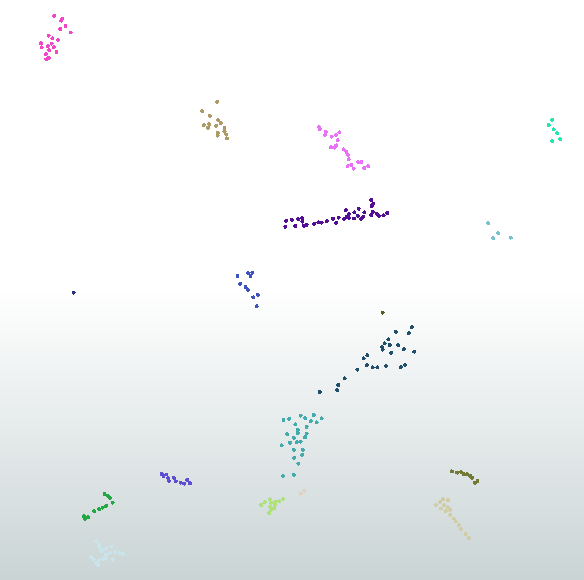I have a shape file with depth readings in various lakes and am trying to find the deapest value in each lake. In order to do this I first need to group the features by vicinity, so that each group represents a lake. Then I can move on to find the highest value in each. Below is a screen dump of my data. What I esentially want to do is to group each of the clusters below by vicinity and then attach a identifying attribute to each group.
I have had a look at neigbourhoodfinder, clustermodeller and a few others, but have not found a way to get any of them to do what I want.
To a human eye the groups in the image below are obvious, and it is sligthy soothing that we can beat the machines now and then, but this time I need the computer to do the work.