



I'm trying to make a dynamic transformer that uses a feature writer to create a temporary file in some format (FFS, CSV, Parquet, doesn't matter) and I need to supply a schema line for the Feature Writer to accept the incoming features. Most readers won't supply one such line, and even though FME is keeps track of some sort of attribute type tag that AttributeMapper is now able to modify, and that AttributeValidator can check with the TYPE operator, there seems to be no way to either get the attribute type map from the features themselves (as shown when hovering the headers of the data inspector columns) or to get the attribute list from the feature type definition (as shown when inspecting a reader and checking the FEATURE_TYPE section of an FMW file).
The only ways to get a schema line seem to be to use a SchemaScanner, a SchemaMapper, an AttributePivoter or a FeatureReader. SchemaScanner seems to be the reccomended option in a case like mine, although that does seem to render the new AttributeManager type setter feature from 2023.0 completely useless, since FeatureWriters can't make use of it without a schema scanner that will completely overwite that.
Is there a way I can get an attributes{} array using the same FME types that are already being used by the cache and inspector? Clearly this isn't something where the features are scanned before writing the FFS cache files, otherwise AttributeManager wouldn't allow setting these.



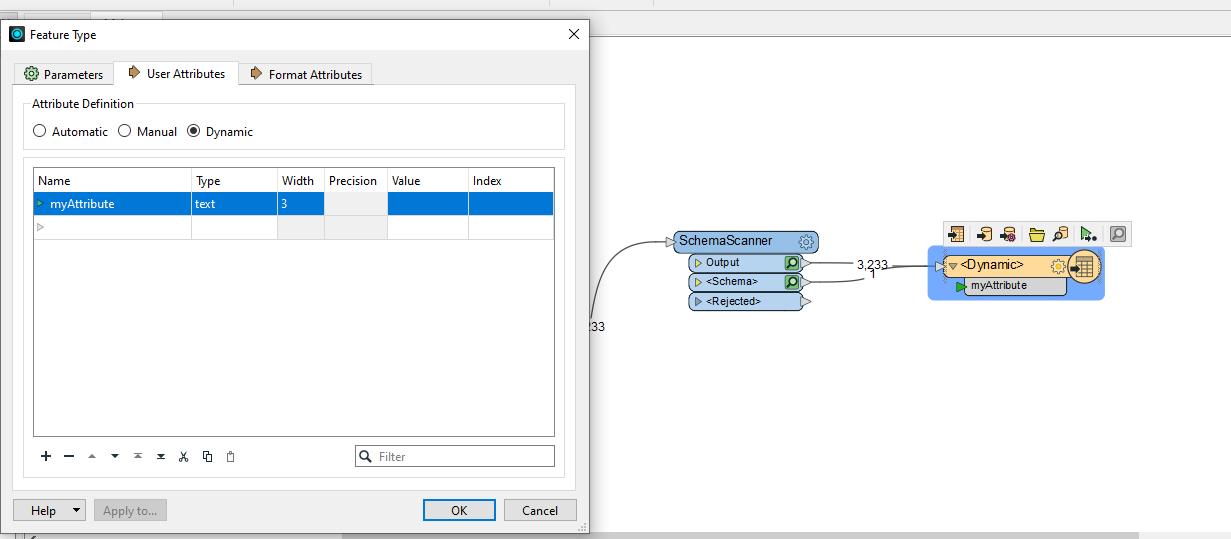 Here I have only one attribute exposed and I've set the width to be 3 (in an AttibuteManager earlier in the workflow). The SchemaScanner has is as "fme_data_type: fme_varchar(7)".
Here I have only one attribute exposed and I've set the width to be 3 (in an AttibuteManager earlier in the workflow). The SchemaScanner has is as "fme_data_type: fme_varchar(7)".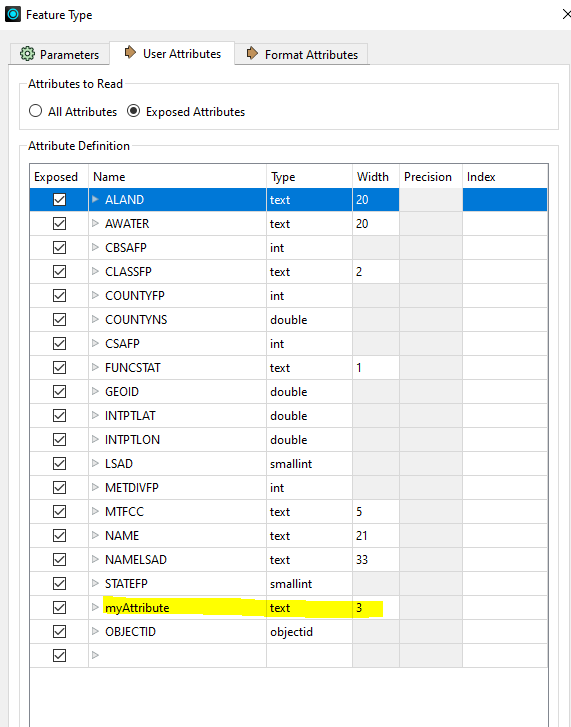 I'm not sure if this help of not for your case
I'm not sure if this help of not for your case