I have a somewhat large (~180k lines, 100 cols) set of features coming out of a database reader that I'm loading into a PythonCaller to run some heavy processing on. I've been doing some profiling and it's a big contributor to slowdown in my workbench. To my surprise, though, the number crunching only represents about 10-20 seconds of the 90 seconds runtime for that node. Most of it is actually spent in the hot loops that run feature.getAttribute (another 25-30s) and feature.setAttribute (about 50s).
Meanwhile, using a FeatureWriter and a FeatureReader, all these features can be written to and read from Parquet files in seemingly less than a second. It's not exactly easy due to how FeatureReaders don't output the path of the file they've written to, and PythonCallers only have one input node, making it difficult to handle passing a temporary output file name, but it cuts down my translation time from 90 seconds down to 9 seconds.
Are these the only two ways of doing things? Do FME's Python bindings have a proper mechanism for bulk-loading a large amount of features like this, or am I stuck doing this by hand (plus handling temporary files)?
Best answer by vlroyrenn
Ok, so, to sumarize the conclusions so far and set a “best answer” on this thread:
Feature loading is unaffected by whether the input is in bulk mode or not, as the feature table shim (which lets transformers like PythonCaller read the features of a feature table as if they were passed individually) doesn’t make the process of extracting the attributes from features any faster
The main source of slowdown for PythonCaller when outputting large amounts of features tends to be pyoutput, which blocks on waiting for the next node to accept the feature (as you can test for yourself by putting a decelerator with a non-zero delay after your PythonCaller)
setAttribute (and getAttribute) is also not insignificant, and there are solid performance gains to be made if you can turn several dozen columns or large list attributes into character-separated strings or JSON strings. Calling setAttribute() for a list of 100 elements is equivalent to calling setAttribute once per element, so it can conceal some large performance penalties.
Bulk mode lets transformers send features in batches instead and merely block on the downstream acceptation of each batch instead of blocking on each feature
PythonCaller cannot normally output in bulk mode, unless it’s re-outputting features that it recieved in bulk mode. FMEFeature objects created in a PythonCaller are not bulked.
The self-contained hack that works best at the moment (excluding writing and reading the input/output in files to circumvent dealing with features altogether) is to initialize a pipeline with an AttributeKeeperFactory and forward all output features there instead of outputting directly, which will give you a stream of bulk features that will remain bulked when passed to pyoutput, therefore not blocking outside of OUTPUT_ON_ATTRIBUTE_CHANGES boundaries (if you chose to enable those, that line is optionnal and can be omitted if you don’t need it), and making feature output almost instant.
According to @daveatsafe, the pipeline’s setCallback cannot be used here, as it was not designed for use in PythonCaller and will crash unless called with callback function defined in the same scope as that pipeline’s allDone(), where it will only output the last batch, ignoring all previous ones. It is functionally useless for this situation.
In order to output batches as they become ready instead of only when closing, you can copy the while True draining loop right after the for row loop that feeds features into the pipeline. Contrary to what the doc says, getOutputFeature does not seem to raise any exceptions on a pipeline that has no feature to output.
Be sure to keep a copy of that draining loop in the close() method, after calling allDone, otherwise you will miss your last batch of features.
An actual dataframe transformer, or changes to PythonCaller to add dataframe input support, is pitched here.
Hopefully these would have an efficient mean of getting around the remaining slow parts of transforming FME features/feature tables into in-memory dataframes back and forth, giving it performance somewhere close to using on-disk files for dataframe I/O
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
In FME 2022.2 (perhaps some lover versions as well), there is an additional function in the PythonCaller which is called to control weather you want the transformer to use Bulk Mode:
def has_support_for(self, support_type): """This method returns whether this PythonCaller supports a certain type. The only supported type is fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM.
:param int support_type: The support type being queried. :returns: True if the passed in support type is supported. :rtype: bool """ if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: # If this is set to return True, FME will pass features to the input() method that # come from a feature table object. This allows for significant performance gains # when processing large numbers of features. # To enable this, the following conditions must be met: # 1) features passed into the input() method cannot be copied or cached for later use # 2) features cannot be read or modified after being passed to self.pyoutput() # 3) Group Processing must not be enabled # Violations will cause undefined behavior. return False
return False
As I understand it (and in my testing) setting the first return to True will use Bulk mode if the incoming feature(s) are in the Bulk Mode structure. I saw significant performance gains when enabling this. I also noticed the feature count changed from being individual to to the typical bulk mode count style.
In FME 2022.2 (perhaps some lover versions as well), there is an additional function in the PythonCaller which is called to control weather you want the transformer to use Bulk Mode:
def has_support_for(self, support_type): """This method returns whether this PythonCaller supports a certain type. The only supported type is fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM.
:param int support_type: The support type being queried. :returns: True if the passed in support type is supported. :rtype: bool """ if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: # If this is set to return True, FME will pass features to the input() method that # come from a feature table object. This allows for significant performance gains # when processing large numbers of features. # To enable this, the following conditions must be met: # 1) features passed into the input() method cannot be copied or cached for later use # 2) features cannot be read or modified after being passed to self.pyoutput() # 3) Group Processing must not be enabled # Violations will cause undefined behavior. return False
return False
As I understand it (and in my testing) setting the first return to True will use Bulk mode if the incoming feature(s) are in the Bulk Mode structure. I saw significant performance gains when enabling this. I also noticed the feature count changed from being individual to to the typical bulk mode count style.
To be clear Feature Table == Bulk Mode
Something else to note is the TempPathNameCreator which can use used when creating temp files. You can use this to create a path name which will get cleaned up when the workspace is finished processing. You can pass the temp path to the FeatureWriter, do your processing and then read them back in again with the confidence that the'll be deleted at the end of the process.
When mentioning the performance reading Parquet files, is that to actually get the data into your business objects, or is that only to open the file and retrieve an iterator over the data?
When mentioning the performance reading Parquet files, is that to actually get the data into your business objects, or is that only to open the file and retrieve an iterator over the data?
Unclear. I'm counting the time it takes for the translation to register as complete after the reader, and how long until the features come up in the inspector, and I tried again piping it to a null writer.
I'm assuming that means all the features get read, but are you suggesting otherwise?
In FME 2022.2 (perhaps some lover versions as well), there is an additional function in the PythonCaller which is called to control weather you want the transformer to use Bulk Mode:
def has_support_for(self, support_type): """This method returns whether this PythonCaller supports a certain type. The only supported type is fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM.
:param int support_type: The support type being queried. :returns: True if the passed in support type is supported. :rtype: bool """ if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: # If this is set to return True, FME will pass features to the input() method that # come from a feature table object. This allows for significant performance gains # when processing large numbers of features. # To enable this, the following conditions must be met: # 1) features passed into the input() method cannot be copied or cached for later use # 2) features cannot be read or modified after being passed to self.pyoutput() # 3) Group Processing must not be enabled # Violations will cause undefined behavior. return False
return False
As I understand it (and in my testing) setting the first return to True will use Bulk mode if the incoming feature(s) are in the Bulk Mode structure. I saw significant performance gains when enabling this. I also noticed the feature count changed from being individual to to the typical bulk mode count style.
Bulk mode is definitely an improvement in terms of the speed of passing data between nodes, but the "Bulk marshalling" I'm talking about is turning large sets of features into large dataframes (or some other structure), which requires, at the very least, something like this:
import fme import fmeobjects import pandas
ATT_NAMES = ["foo", "bar", "baz"]
class FeatureProcessor(object): def __init__(self): self.dataset_features = [] # Accumulate features as fast as possible self.input = self.dataset_features.append
def close(self): print("Unmarshalling") feature_records = [ tuple(feature.getAttribute(att_name) for att_name in ATT_NAMES) for feature in self.dataset_features ] print("Done unmarshalling")
print("Building dataframe") df = pandas.DataFrame.from_records(feature_records, columns=ATT_NAMES) print("Done building dataframe") del self.dataset_features del feature_records
print("Processing") # # Do stuff with your dataframe # print("Done processing")
print("Marshalling results") for row_tuple in df.itertuples(): feature = fmeobjects.FMEFeature()
for col in ATT_NAMES: val = getattr(row_tuple, col) feature.setAttribute(col, val)
def has_support_for(self, support_type): if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: return True
return False
That process is both pretty involved code-wise (as you can see) and fairly slow, to the point where the marshalling and unmarshalling steps take several times longer than the actual processing, as mentionned in my original post.
Bulk mode is definitely an improvement in terms of the speed of passing data between nodes, but the "Bulk marshalling" I'm talking about is turning large sets of features into large dataframes (or some other structure), which requires, at the very least, something like this:
import fme import fmeobjects import pandas
ATT_NAMES = ["foo", "bar", "baz"]
class FeatureProcessor(object): def __init__(self): self.dataset_features = [] # Accumulate features as fast as possible self.input = self.dataset_features.append
def close(self): print("Unmarshalling") feature_records = [ tuple(feature.getAttribute(att_name) for att_name in ATT_NAMES) for feature in self.dataset_features ] print("Done unmarshalling")
print("Building dataframe") df = pandas.DataFrame.from_records(feature_records, columns=ATT_NAMES) print("Done building dataframe") del self.dataset_features del feature_records
print("Processing") # # Do stuff with your dataframe # print("Done processing")
print("Marshalling results") for row_tuple in df.itertuples(): feature = fmeobjects.FMEFeature()
for col in ATT_NAMES: val = getattr(row_tuple, col) feature.setAttribute(col, val)
def has_support_for(self, support_type): if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: return True
return False
That process is both pretty involved code-wise (as you can see) and fairly slow, to the point where the marshalling and unmarshalling steps take several times longer than the actual processing, as mentionned in my original post.
I would expect (!) that if you tell Pandas to create a dataframe over a known file format, that it would imply create iterators over the contents and read on demand, rather than reading all into memory at once, which is what I believe you're doing above.
At the very least, make sure you're sending as few attributes as possible into the PythonCaller, e.g. using an AttributeKeeper in front.
Bulk mode is definitely an improvement in terms of the speed of passing data between nodes, but the "Bulk marshalling" I'm talking about is turning large sets of features into large dataframes (or some other structure), which requires, at the very least, something like this:
import fme import fmeobjects import pandas
ATT_NAMES = ["foo", "bar", "baz"]
class FeatureProcessor(object): def __init__(self): self.dataset_features = [] # Accumulate features as fast as possible self.input = self.dataset_features.append
def close(self): print("Unmarshalling") feature_records = [ tuple(feature.getAttribute(att_name) for att_name in ATT_NAMES) for feature in self.dataset_features ] print("Done unmarshalling")
print("Building dataframe") df = pandas.DataFrame.from_records(feature_records, columns=ATT_NAMES) print("Done building dataframe") del self.dataset_features del feature_records
print("Processing") # # Do stuff with your dataframe # print("Done processing")
print("Marshalling results") for row_tuple in df.itertuples(): feature = fmeobjects.FMEFeature()
for col in ATT_NAMES: val = getattr(row_tuple, col) feature.setAttribute(col, val)
def has_support_for(self, support_type): if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: return True
return False
That process is both pretty involved code-wise (as you can see) and fairly slow, to the point where the marshalling and unmarshalling steps take several times longer than the actual processing, as mentionned in my original post.
As far as I'm aware, Pandas by itself does not have support for disk streaming and, yes, will actually read the entire file into memory to create the dataframe, just like I'm doing with the features code sample above. I'm working on 120 columns and I actually do need to run calculations over all of them (hence why I'm doing this with Pandas instead of using FME-native nodes, which have a hard time dealing with so many columns). Doing the processing in one go inside a dataframe is actually the better way of doing that I've found, as running the calculations on a per-feature basis (with a numpy array, not bare Python maths) causes the translation time for that node to almost triple.
The performance issue really does seem to just be the overhead of calling getAttribute and setAttribute some 21 million times each.
Bulk mode is definitely an improvement in terms of the speed of passing data between nodes, but the "Bulk marshalling" I'm talking about is turning large sets of features into large dataframes (or some other structure), which requires, at the very least, something like this:
import fme import fmeobjects import pandas
ATT_NAMES = ["foo", "bar", "baz"]
class FeatureProcessor(object): def __init__(self): self.dataset_features = [] # Accumulate features as fast as possible self.input = self.dataset_features.append
def close(self): print("Unmarshalling") feature_records = [ tuple(feature.getAttribute(att_name) for att_name in ATT_NAMES) for feature in self.dataset_features ] print("Done unmarshalling")
print("Building dataframe") df = pandas.DataFrame.from_records(feature_records, columns=ATT_NAMES) print("Done building dataframe") del self.dataset_features del feature_records
print("Processing") # # Do stuff with your dataframe # print("Done processing")
print("Marshalling results") for row_tuple in df.itertuples(): feature = fmeobjects.FMEFeature()
for col in ATT_NAMES: val = getattr(row_tuple, col) feature.setAttribute(col, val)
def has_support_for(self, support_type): if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: return True
return False
That process is both pretty involved code-wise (as you can see) and fairly slow, to the point where the marshalling and unmarshalling steps take several times longer than the actual processing, as mentionned in my original post.
21 million function calls is pretty hard core, I'm not surprised that it takes a while.
Also, creating many instances of fmeobjects.FMEFeature is also not without cost.
If performance is crucial to you, perhaps it could be interesting for Safe to hear about your use case and to see if there's room for improvement in their Python wrapper code.
Unclear. I'm counting the time it takes for the translation to register as complete after the reader, and how long until the features come up in the inspector, and I tried again piping it to a null writer.
I'm assuming that means all the features get read, but are you suggesting otherwise?
I notice that you have feature caching enabled, which is known for having an big impact on performance. Have you tried turning off feature caching and trying again?
It's not going to impact the Python code as such, but the rest of the workspace should run noticeably faster.
Bulk mode is definitely an improvement in terms of the speed of passing data between nodes, but the "Bulk marshalling" I'm talking about is turning large sets of features into large dataframes (or some other structure), which requires, at the very least, something like this:
import fme import fmeobjects import pandas
ATT_NAMES = ["foo", "bar", "baz"]
class FeatureProcessor(object): def __init__(self): self.dataset_features = [] # Accumulate features as fast as possible self.input = self.dataset_features.append
def close(self): print("Unmarshalling") feature_records = [ tuple(feature.getAttribute(att_name) for att_name in ATT_NAMES) for feature in self.dataset_features ] print("Done unmarshalling")
print("Building dataframe") df = pandas.DataFrame.from_records(feature_records, columns=ATT_NAMES) print("Done building dataframe") del self.dataset_features del feature_records
print("Processing") # # Do stuff with your dataframe # print("Done processing")
print("Marshalling results") for row_tuple in df.itertuples(): feature = fmeobjects.FMEFeature()
for col in ATT_NAMES: val = getattr(row_tuple, col) feature.setAttribute(col, val)
def has_support_for(self, support_type): if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: return True
return False
That process is both pretty involved code-wise (as you can see) and fairly slow, to the point where the marshalling and unmarshalling steps take several times longer than the actual processing, as mentionned in my original post.
Well, basically it boils down to Big SQL Query -> Transformer that uses a Dataframe for computing -> Big SQL insertion, with some lookup and joining on the side. I used to do the SQL and insertion in Python as well (most dataframe libraries can populate themselves with an SQL query), so I have a point of comparison for the performance. I've just recently started porting some of these scripts over to FME, and i'm trying to do things "the right way" by moving the I/O into its own nodes, but the dataframe conversion between these "Dataframe transformers" is having a serious impact on runtime.
I'll see if I can't raise that in the AC ideas section.
Unclear. I'm counting the time it takes for the translation to register as complete after the reader, and how long until the features come up in the inspector, and I tried again piping it to a null writer.
I'm assuming that means all the features get read, but are you suggesting otherwise?
Yes, the database query takes a few minutes (180k lines out of a few dozen millions is hard on the DB), and caching lets me test the performance of the transformation without having to wait on it every time. I tried, and caching turns out to be faster while I'm testing this part.
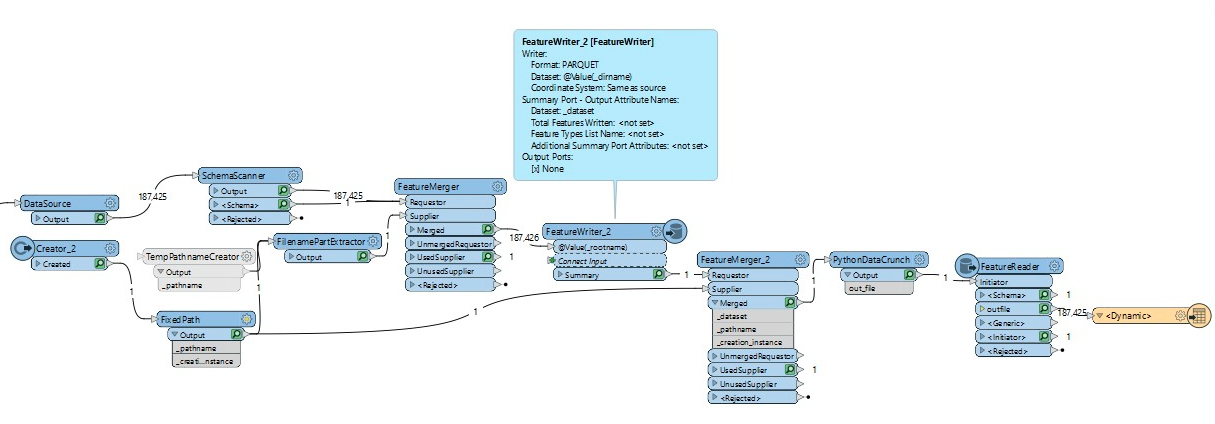
Something else to note is the TempPathNameCreator which can use used when creating temp files. You can use this to create a path name which will get cleaned up when the workspace is finished processing. You can pass the temp path to the FeatureWriter, do your processing and then read them back in again with the confidence that the'll be deleted at the end of the process.
Ok, I tried the temporary file thing and it works, but, erm...
I might be missing a more obvious and/or clean way of doing it, but it's a lot of fluff to put around a single Python Caller, out of potentially many.
The first FeatureMerget is to get the "Dataset" (directory) and "Feature Type" (file name) attributes written on each feature so the FeatureWriter knows where to put them, and the second is to wait until the writer is sone before sending the input path to PythonDataCrunch.
Bulk mode is definitely an improvement in terms of the speed of passing data between nodes, but the "Bulk marshalling" I'm talking about is turning large sets of features into large dataframes (or some other structure), which requires, at the very least, something like this:
import fme import fmeobjects import pandas
ATT_NAMES = ["foo", "bar", "baz"]
class FeatureProcessor(object): def __init__(self): self.dataset_features = [] # Accumulate features as fast as possible self.input = self.dataset_features.append
def close(self): print("Unmarshalling") feature_records = [ tuple(feature.getAttribute(att_name) for att_name in ATT_NAMES) for feature in self.dataset_features ] print("Done unmarshalling")
print("Building dataframe") df = pandas.DataFrame.from_records(feature_records, columns=ATT_NAMES) print("Done building dataframe") del self.dataset_features del feature_records
print("Processing") # # Do stuff with your dataframe # print("Done processing")
print("Marshalling results") for row_tuple in df.itertuples(): feature = fmeobjects.FMEFeature()
for col in ATT_NAMES: val = getattr(row_tuple, col) feature.setAttribute(col, val)
def has_support_for(self, support_type): if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: return True
return False
That process is both pretty involved code-wise (as you can see) and fairly slow, to the point where the marshalling and unmarshalling steps take several times longer than the actual processing, as mentionned in my original post.
I just created the idea, for those who are interested, though these seem to take several years to get through, so I won't keep my fingers crossed.
In FME 2022.2 (perhaps some lover versions as well), there is an additional function in the PythonCaller which is called to control weather you want the transformer to use Bulk Mode:
def has_support_for(self, support_type): """This method returns whether this PythonCaller supports a certain type. The only supported type is fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM.
:param int support_type: The support type being queried. :returns: True if the passed in support type is supported. :rtype: bool """ if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: # If this is set to return True, FME will pass features to the input() method that # come from a feature table object. This allows for significant performance gains # when processing large numbers of features. # To enable this, the following conditions must be met: # 1) features passed into the input() method cannot be copied or cached for later use # 2) features cannot be read or modified after being passed to self.pyoutput() # 3) Group Processing must not be enabled # Violations will cause undefined behavior. return False
return False
As I understand it (and in my testing) setting the first return to True will use Bulk mode if the incoming feature(s) are in the Bulk Mode structure. I saw significant performance gains when enabling this. I also noticed the feature count changed from being individual to to the typical bulk mode count style.
Ok, having spent all day running tests and trying hypotheses around this question, it seems like your were actually partly right with your bulk mode suggestion, @virtualcitymatt , but not for the reasons I expected.
As it turns out, the source of my data is an ODBC 3.x database reader, which doesn't output in bulk mode, and that's never mentionned anywhere in the doc or interface or told to you in the logs, whereas the Parquet reader does output in bulk mode. My first clue that this was the case was that PythonCaller allowed me to store the features passed to input() and read them in close(), which is forbidden in Bulk mode†, and will cause the translation to crash if you do.
† "1) features passed into the input() method cannot be copied or cached for later use"
Now that this has been cleared up, let's see the performance improvements that bulk mode brings when converting all attributes into records in preparation for building a dataframe:
Bulk input (cached), support_type == False, getAttr in close(): 4s to recieve features in input() + 23s to convert to tuples in close()
Bulk input(cached), support_type == True, getAttr in close(): Undefined behavior
Bulk input(cached), support_type == False, getAttr in input(): 25s to process all features into tuples
Bulk input(cached), support_type == True, getAttr in input(): 30s to process all features into tuples
Non-bulk input (cached), getAttr in input(): 30s to process all features into tuples
Non-bulk input (cached), getAttr in close(): 7s to recieve features in input() + 24s to convert to tuples in close()
This was all done with the same 187 333 features (with 109 attributes each), coming either from an ODBC reader or a Parquet reader, with the parquet file generated from the output of the ODBC reader. Both readers are not actually running and having their output pulled from the cache, so input speed is controlled.
In conclusion, bulk mode doesn't improve input performance when bulk-loading attributes into a dataframe, and by the looks of it, outputting features in close() means your output data will not be in bulk mode either.
Something else to note is the TempPathNameCreator which can use used when creating temp files. You can use this to create a path name which will get cleaned up when the workspace is finished processing. You can pass the temp path to the FeatureWriter, do your processing and then read them back in again with the confidence that the'll be deleted at the end of the process.
Yeah, actually this is also something which has annoyed me a bit about the TempPathNameCreator. You should be able to control in some way the way in which the path is created so you can just stick it in the main flow.
Usually the FeatureWriter should pass you the dataset and FeatureType but I think there is a bug in FME 2022.2 which is preventing this.
Ideally it'd just be TempPathNameCreator>FeatureWriter>ExternalProcess>FeatureReader. I think I will create an idea to get the TempPathNameCreator a few more options.
Ok, having spent all day running tests and trying hypotheses around this question, it seems like your were actually partly right with your bulk mode suggestion, @virtualcitymatt , but not for the reasons I expected.
As it turns out, the source of my data is an ODBC 3.x database reader, which doesn't output in bulk mode, and that's never mentionned anywhere in the doc or interface or told to you in the logs, whereas the Parquet reader does output in bulk mode. My first clue that this was the case was that PythonCaller allowed me to store the features passed to input() and read them in close(), which is forbidden in Bulk mode†, and will cause the translation to crash if you do.
† "1) features passed into the input() method cannot be copied or cached for later use"
Now that this has been cleared up, let's see the performance improvements that bulk mode brings when converting all attributes into records in preparation for building a dataframe:
Bulk input (cached), support_type == False, getAttr in close(): 4s to recieve features in input() + 23s to convert to tuples in close()
Bulk input(cached), support_type == True, getAttr in close(): Undefined behavior
Bulk input(cached), support_type == False, getAttr in input(): 25s to process all features into tuples
Bulk input(cached), support_type == True, getAttr in input(): 30s to process all features into tuples
Non-bulk input (cached), getAttr in input(): 30s to process all features into tuples
Non-bulk input (cached), getAttr in close(): 7s to recieve features in input() + 24s to convert to tuples in close()
This was all done with the same 187 333 features (with 109 attributes each), coming either from an ODBC reader or a Parquet reader, with the parquet file generated from the output of the ODBC reader. Both readers are not actually running and having their output pulled from the cache, so input speed is controlled.
In conclusion, bulk mode doesn't improve input performance when bulk-loading attributes into a dataframe, and by the looks of it, outputting features in close() means your output data will not be in bulk mode either.
Pretty interesting test results. I definitely would have expected BulkMode to speed up your process here. It would be interesting to know if with small feature (less attributes) how much of a difference bulk mode has vs not Bulk Mode compared to your large features which see no improvement.
Based on my limited knowledge it was my assumption that Feature Tables/Bulk Mode was FME's equivalent to the dataframe. I guess though FME is rather catered to processing per feature rather than the whole dataset.
FME also has an RCaller. I wonder how the performance compares building the R dataframe in FME vs how you're doing it in the PythonCaller.
A bit sad that your data isn't being read in Bulk Mode. Are you working with FME 2023? They're always adding Bulk Mode support - It could be they added support in FME 2023. Usually in the log you can tell when Bulk Mode is lost but if it's not created in the Reader the only way you can tell is the way the feature count is changing. If you see big jumps in the feature counts then BulkMode is active. If the counts are looking sequential then it's working on individual features.
I'm my view when processing in bulk mode you effectively only have one feature (depending on the number of features contained in the Bulk Mode feature table) - similar to when working with a pointcloud or raster. It seems like it should be fairly doable to change the structure of these Bulk Features into a dataframe. It seem like quite a lost opportunity here. I think the idea you created is on point!
Bulk mode is definitely an improvement in terms of the speed of passing data between nodes, but the "Bulk marshalling" I'm talking about is turning large sets of features into large dataframes (or some other structure), which requires, at the very least, something like this:
import fme import fmeobjects import pandas
ATT_NAMES = ["foo", "bar", "baz"]
class FeatureProcessor(object): def __init__(self): self.dataset_features = [] # Accumulate features as fast as possible self.input = self.dataset_features.append
def close(self): print("Unmarshalling") feature_records = [ tuple(feature.getAttribute(att_name) for att_name in ATT_NAMES) for feature in self.dataset_features ] print("Done unmarshalling")
print("Building dataframe") df = pandas.DataFrame.from_records(feature_records, columns=ATT_NAMES) print("Done building dataframe") del self.dataset_features del feature_records
print("Processing") # # Do stuff with your dataframe # print("Done processing")
print("Marshalling results") for row_tuple in df.itertuples(): feature = fmeobjects.FMEFeature()
for col in ATT_NAMES: val = getattr(row_tuple, col) feature.setAttribute(col, val)
def has_support_for(self, support_type): if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: return True
return False
That process is both pretty involved code-wise (as you can see) and fairly slow, to the point where the marshalling and unmarshalling steps take several times longer than the actual processing, as mentionned in my original post.
Excellent idea, upvoted. Don't be discouraged by the age of some of the other ideas. Some ideas get implemented fairly quickly, it's mostly a question of perceived business value by those deciding. If you ever find yourself at an FME user conference, don't hesitate to champion your idea whenever you see someone from Safe, it can make a real difference.
Ok, having spent all day running tests and trying hypotheses around this question, it seems like your were actually partly right with your bulk mode suggestion, @virtualcitymatt , but not for the reasons I expected.
As it turns out, the source of my data is an ODBC 3.x database reader, which doesn't output in bulk mode, and that's never mentionned anywhere in the doc or interface or told to you in the logs, whereas the Parquet reader does output in bulk mode. My first clue that this was the case was that PythonCaller allowed me to store the features passed to input() and read them in close(), which is forbidden in Bulk mode†, and will cause the translation to crash if you do.
† "1) features passed into the input() method cannot be copied or cached for later use"
Now that this has been cleared up, let's see the performance improvements that bulk mode brings when converting all attributes into records in preparation for building a dataframe:
Bulk input (cached), support_type == False, getAttr in close(): 4s to recieve features in input() + 23s to convert to tuples in close()
Bulk input(cached), support_type == True, getAttr in close(): Undefined behavior
Bulk input(cached), support_type == False, getAttr in input(): 25s to process all features into tuples
Bulk input(cached), support_type == True, getAttr in input(): 30s to process all features into tuples
Non-bulk input (cached), getAttr in input(): 30s to process all features into tuples
Non-bulk input (cached), getAttr in close(): 7s to recieve features in input() + 24s to convert to tuples in close()
This was all done with the same 187 333 features (with 109 attributes each), coming either from an ODBC reader or a Parquet reader, with the parquet file generated from the output of the ODBC reader. Both readers are not actually running and having their output pulled from the cache, so input speed is controlled.
In conclusion, bulk mode doesn't improve input performance when bulk-loading attributes into a dataframe, and by the looks of it, outputting features in close() means your output data will not be in bulk mode either.
> A bit sad that your data isn't being read in Bulk Mode.
Well, it's being passed in bulk mode, but PythonCaller can only read/modify that data feature by feature, anyway. According to this question, the main point is to let you alter the features as needed in input() and have the output still be in bulk mode for the downstream transformers. Loading all the data in one big R-like dataframe and outputting it in close() is not the situation they had in mind when adding bulk mode to PythonCaller.
> Are you working with FME 2023?
2022.1 at the moment. The PythonCaller clearly can handle bulk mode, since the feature count at the input (and the output if I use pyoutput() inside input() instead of inside of close()) moves up in jumps of 100k features, which lines up with how you described it.
> FME also has an RCaller. I wonder how the performance compares building the R dataframe in FME vs how you're doing it in the PythonCaller.
The doc says R recieves the full feature set as a dataframe (probably passed as some sort of SQLite-type database, judging by how sqldf is required for RCaller to run), but most baffling of all...
"RCaller (InlineQueryFactory): Splitting bulk features into individual features"
😞
EDIT: My bad, it supports Bulk mode starting with 2023.0
> Based on my limited knowledge it was my assumption that Feature Tables/Bulk Mode was FME's equivalent to the dataframe.
It's so close to being that! The only issue is the way they handle feature reading on the Python script side of things.
Ok, having spent all day running tests and trying hypotheses around this question, it seems like your were actually partly right with your bulk mode suggestion, @virtualcitymatt , but not for the reasons I expected.
As it turns out, the source of my data is an ODBC 3.x database reader, which doesn't output in bulk mode, and that's never mentionned anywhere in the doc or interface or told to you in the logs, whereas the Parquet reader does output in bulk mode. My first clue that this was the case was that PythonCaller allowed me to store the features passed to input() and read them in close(), which is forbidden in Bulk mode†, and will cause the translation to crash if you do.
† "1) features passed into the input() method cannot be copied or cached for later use"
Now that this has been cleared up, let's see the performance improvements that bulk mode brings when converting all attributes into records in preparation for building a dataframe:
Bulk input (cached), support_type == False, getAttr in close(): 4s to recieve features in input() + 23s to convert to tuples in close()
Bulk input(cached), support_type == True, getAttr in close(): Undefined behavior
Bulk input(cached), support_type == False, getAttr in input(): 25s to process all features into tuples
Bulk input(cached), support_type == True, getAttr in input(): 30s to process all features into tuples
Non-bulk input (cached), getAttr in input(): 30s to process all features into tuples
Non-bulk input (cached), getAttr in close(): 7s to recieve features in input() + 24s to convert to tuples in close()
This was all done with the same 187 333 features (with 109 attributes each), coming either from an ODBC reader or a Parquet reader, with the parquet file generated from the output of the ODBC reader. Both readers are not actually running and having their output pulled from the cache, so input speed is controlled.
In conclusion, bulk mode doesn't improve input performance when bulk-loading attributes into a dataframe, and by the looks of it, outputting features in close() means your output data will not be in bulk mode either.
Based on my testing now that I've switched to FME Workbench Form and FME Server Flow 2023, I can say that, for my use-case, the RCaller turns out to be around 40% faster (from about 65s to 40s) than the PythonCaller, accounting for R's lower performance but also the automatic bulk feature loading and returning. So I guess I'll be using that for now.
The reason performance went from 90s in my OP to 65s just here is because it turns out that getAttribute and SetAttribute on list values are equivalent in terms of speed to getting/setting as many columns as there are elements in your list, so by returning the resulting value as a comma-separated string, I've managed to drastically improve performance across all scripted transformers, but R still ends up faster than Python in my situation.
Ok, having spent all day running tests and trying hypotheses around this question, it seems like your were actually partly right with your bulk mode suggestion, @virtualcitymatt , but not for the reasons I expected.
As it turns out, the source of my data is an ODBC 3.x database reader, which doesn't output in bulk mode, and that's never mentionned anywhere in the doc or interface or told to you in the logs, whereas the Parquet reader does output in bulk mode. My first clue that this was the case was that PythonCaller allowed me to store the features passed to input() and read them in close(), which is forbidden in Bulk mode†, and will cause the translation to crash if you do.
† "1) features passed into the input() method cannot be copied or cached for later use"
Now that this has been cleared up, let's see the performance improvements that bulk mode brings when converting all attributes into records in preparation for building a dataframe:
Bulk input (cached), support_type == False, getAttr in close(): 4s to recieve features in input() + 23s to convert to tuples in close()
Bulk input(cached), support_type == True, getAttr in close(): Undefined behavior
Bulk input(cached), support_type == False, getAttr in input(): 25s to process all features into tuples
Bulk input(cached), support_type == True, getAttr in input(): 30s to process all features into tuples
Non-bulk input (cached), getAttr in input(): 30s to process all features into tuples
Non-bulk input (cached), getAttr in close(): 7s to recieve features in input() + 24s to convert to tuples in close()
This was all done with the same 187 333 features (with 109 attributes each), coming either from an ODBC reader or a Parquet reader, with the parquet file generated from the output of the ODBC reader. Both readers are not actually running and having their output pulled from the cache, so input speed is controlled.
In conclusion, bulk mode doesn't improve input performance when bulk-loading attributes into a dataframe, and by the looks of it, outputting features in close() means your output data will not be in bulk mode either.
Very interesting, thanks for sharing your findings!
I’ve had to return to this issue recently and tried running some more benchmarks to see how much overhead there is in the PythonCaller feature output loop. As it turns out, quite a lot.
Here, I try an unusual approach of loading a CSV file (for instance) into FME features by pre-creating the amount of features needed as a feature table, just to see how much performance is impacted.
The flow goes like this (I’m having issues embedding screenshots at the moment):
The code for Python_PreCountLines is just loading the file and returning the row count, which is then passed as “Number of Copies” to the Cloner.
The code for Python_PopulateFeatures is structured as follows:
import fme import fmeobjects import polars as pl import time
class FeatureProcessor(object): def __init__(self): # Load file into dataframe and do any processing needed # my_dataframe = ... self.data_out = my_dataframe self.data_out_iter = my_dataframe.iter_rows(named=True)
def has_support_for(self, support_type): if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: return True
return False
Notice that I have timing checkpoints inside input() so I can compare the average timing for each step of the process (I have normalized the notation to microseconds by hand for readability). Note that feature caching and counting is on.
Category
Reported timing averages (6 columns)
Reuse input features (Cloner), Feature tables on
INFORM|Feature population time: 10.55 µs INFORM|Feature output time: 5.93 µs Total workbench time: 1m45.7s
Reuse input features (Cloner), Feature tables off
INFORM|Feature population time: 10.95 µs INFORM|Feature output time: 45.71 µs Total workbench time: 4m09.4s
Create features in Python No feature tables
INFORM|Feature creation time: 9.76 µs INFORM|Feature population time: 10.42 µs INFORM|Feature output time: 68.14 µs Total workbench time: 4m54.9s
Feature output time is by far (unless you populate several dozen columns) the main contributor to converting Python data into FME features, and getting FME to enable feature tables on output cuts it down tenfold, and total Python_PopulateFeatures execution time (for a 2.7M lines CSV file, 6 output columns) by almost 60%. It frees up enough overhead that, even if I add in the otherwise wasteful cost of loading the file a second time to get the line count in Python_PreCountLines (which takes 13 seconds), this is still an enormous performance gain.
Obviously this is a fairly clumsy setup and mainly serves to illustrate how much feature tables improve data flow speeds, but I think it also shows how limited the current Python transformer in terms of I/O overhead. I wish we could seamlessly have that sort of performance for both input and output to make working with dataframes less slow.
The whole cloner thing made me realize that pyoutput is the slow part, and try to look into ways of going around it. As it turns out, you can have an AttributeKeeper factory package all your features into bulk feature tables as part of the Python caller, and output the “pre-bulked” features coming out of that factory with pyoutput.
class FeatureProcessor(object): def __init__(self): if not hasattr(self, "factory_name"): self.factory_name = "PythonCaller_3"
keep_encoded = ','.join([self.session.encodeToFMEParsableText(attr) for attr in attributes_to_keep]) on_change_encoded = ','.join([self.session.encodeToFMEParsableText(attr) for attr in bulk_out_on_change])
while True: out_feat = self.keeper_factory.getOutputFeature()
if out_feat is None: break
self.pyoutput(out_feat)
def has_support_for(self, support_type): if support_type == fmeobjects.FME_SUPPORT_FEATURE_TABLE_SHIM: return True
return False
I could probably use setCallback instead of getOutputFeature, but can’t seem to get setCallback to work correctly at the moment and the difference doesn’t really matter for my current dataframe use case.
At any rate, it cuts down time spent on serialization and output almost completely.
It’s not “free”, skipping the output for loop entirely gets me 2.5s execution time reading a file that takes 5.0s with the code I’m presenting, but against 11.9s for doing the regular pyoutput() way of doing things, it is an enormous gain.
In fact, if I do a comparison with the same file I used in my previous post:
No output: 23.9s
Clone hack: 1m41s (Cloner + PopulateFeatures only, no PreCountLines)
Ok, so, to sumarize the conclusions so far and set a “best answer” on this thread:
Feature loading is unaffected by whether the input is in bulk mode or not, as the feature table shim (which lets transformers like PythonCaller read the features of a feature table as if they were passed individually) doesn’t make the process of extracting the attributes from features any faster
The main source of slowdown for PythonCaller when outputting large amounts of features tends to be pyoutput, which blocks on waiting for the next node to accept the feature (as you can test for yourself by putting a decelerator with a non-zero delay after your PythonCaller)
setAttribute (and getAttribute) is also not insignificant, and there are solid performance gains to be made if you can turn several dozen columns or large list attributes into character-separated strings or JSON strings. Calling setAttribute() for a list of 100 elements is equivalent to calling setAttribute once per element, so it can conceal some large performance penalties.
Bulk mode lets transformers send features in batches instead and merely block on the downstream acceptation of each batch instead of blocking on each feature
PythonCaller cannot normally output in bulk mode, unless it’s re-outputting features that it recieved in bulk mode. FMEFeature objects created in a PythonCaller are not bulked.
The self-contained hack that works best at the moment (excluding writing and reading the input/output in files to circumvent dealing with features altogether) is to initialize a pipeline with an AttributeKeeperFactory and forward all output features there instead of outputting directly, which will give you a stream of bulk features that will remain bulked when passed to pyoutput, therefore not blocking outside of OUTPUT_ON_ATTRIBUTE_CHANGES boundaries (if you chose to enable those, that line is optionnal and can be omitted if you don’t need it), and making feature output almost instant.
According to @daveatsafe, the pipeline’s setCallback cannot be used here, as it was not designed for use in PythonCaller and will crash unless called with callback function defined in the same scope as that pipeline’s allDone(), where it will only output the last batch, ignoring all previous ones. It is functionally useless for this situation.
In order to output batches as they become ready instead of only when closing, you can copy the while True draining loop right after the for row loop that feeds features into the pipeline. Contrary to what the doc says, getOutputFeature does not seem to raise any exceptions on a pipeline that has no feature to output.
Be sure to keep a copy of that draining loop in the close() method, after calling allDone, otherwise you will miss your last batch of features.
An actual dataframe transformer, or changes to PythonCaller to add dataframe input support, is pitched here.
Hopefully these would have an efficient mean of getting around the remaining slow parts of transforming FME features/feature tables into in-memory dataframes back and forth, giving it performance somewhere close to using on-disk files for dataframe I/O
For people wondering, the main reason I’m going through the trouble of this whole FactoryPipeline hack instead of using files is that
TempPathnameCreator is clumsy to use here, because it creates one new temporary file per input feature, so that needs to be a join
Passing the output file path to the Python caller while also passing features to process on the same port complexifies the resulting Python code by a fair amount
The Parquet writer (not the reader) specifically uses the Dataset as the destination folder, not file, which means the paths being created by TempPathnameCreator have to be broken up by a FilenamePartExtractor in the middle
SchemaScanner is intended for things like coercing the strings of CSV files into smaller types, while I actually needed to preserve the attribute types of incoming features
Any file not created by TempPathnameCreator is not guarenteed to be cleaned up after the translation
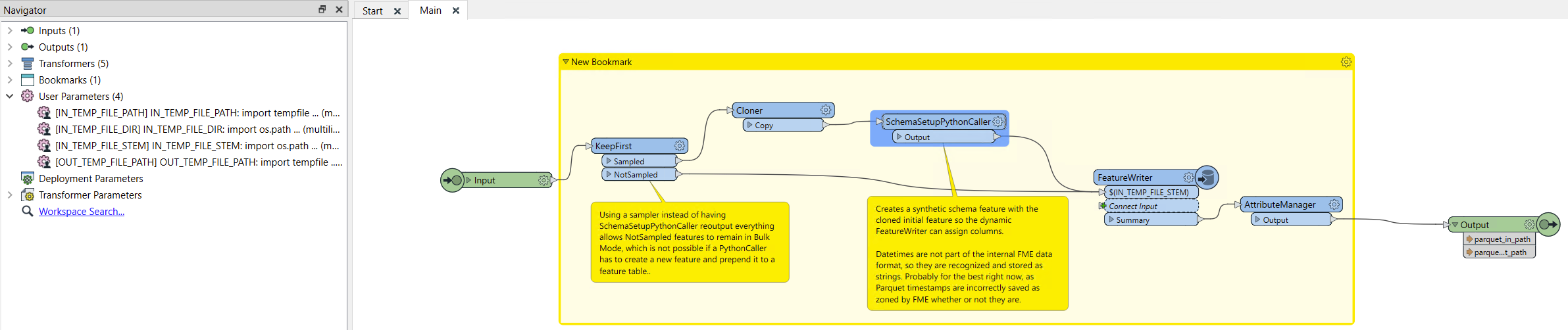
As I’ve learned from recent discussions with Safe employees, though, it turns out that the Python tempfile module is altered to create files inside the FME_TEMP directory, that actually will be deleted when the translation ends. This is significant because it allows creating and passing temporary file names as static user parameters instead of feature attributes. Armed with this knowledge and what I’ve learned over the past year about Bulk Mode (and all its quirks), the fmeobjects library, workarounds to various FME Python issues, the inner workings of stock transformers in fmesuite.fmx, and the Parquet format, I’ve managed to wrap up all of this into a single Custom transformer.
Custom transformer in actionCustom transformer definition
From my testing, using the same 106 columns test file I had last year, Python feature reading time (with Bulked input features) is about 3 times faster than just extracting the attributes from each feature in the input() method (from 58.1s to 19.8s) and feature output time compated to the FactoryPipeline hack sees a 2x speedup, going from an already respectable 20s down to 9.6s (including both the duration of write_parquet() and the follow-up FeatureReader).
I do think that’s going to be the limit in terms of how fast features can be passed back and forth between FME and Python, though, at least for the next few releases. It also doesn’t solve the specific pain point I evoked in my community idea on the matter of date parsing, since those are kept as strings (as mentionned in the annotation on the screenshot above ass well as the transformer’s doc). Still, I think it’s a much cleaner solution, both on the Python side and on the workbench side, than anything else that has come up before.









 I'm assuming that means all the features get read, but are you suggesting otherwise?
I'm assuming that means all the features get read, but are you suggesting otherwise?