


@DaveAtSafe
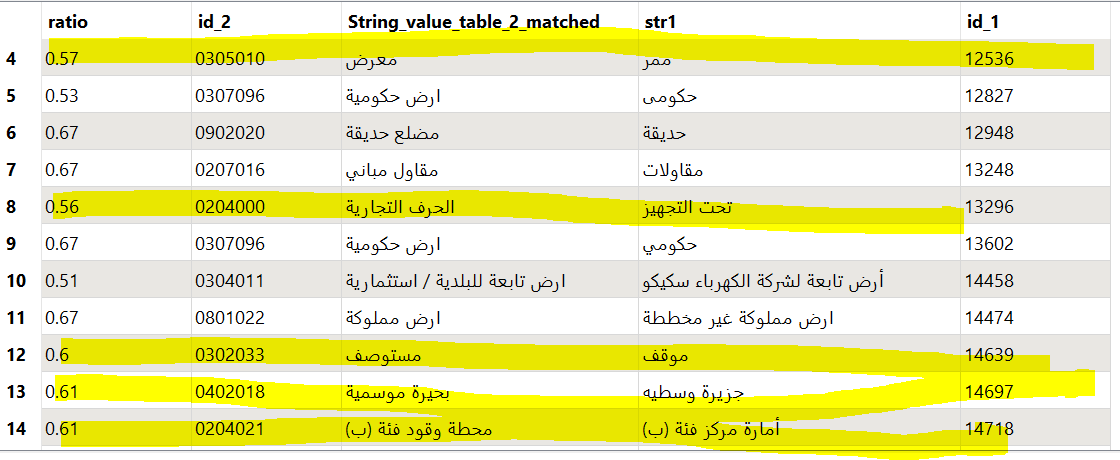
hello, Dave, we are using the fuzzyStringcompare software in order to compare Arabic strings from 2 different data set, but it's not giving the expected result even when the ration is high,
Since you have been involved in this costom transformer any idea on how we could fix this
Thanks
")
