Hi guys,
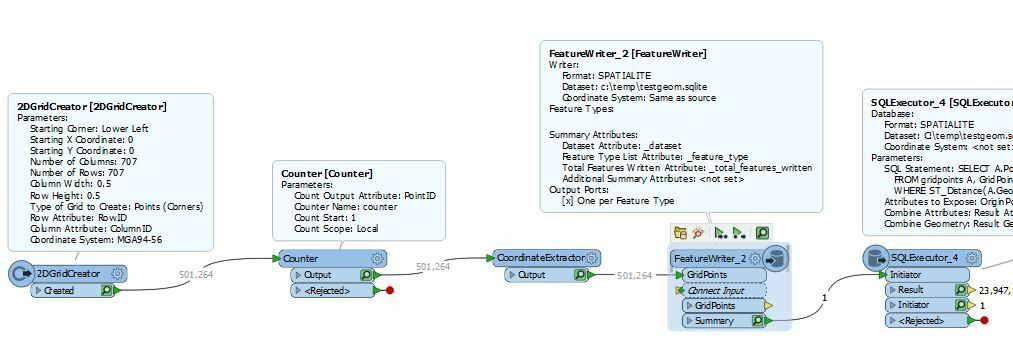
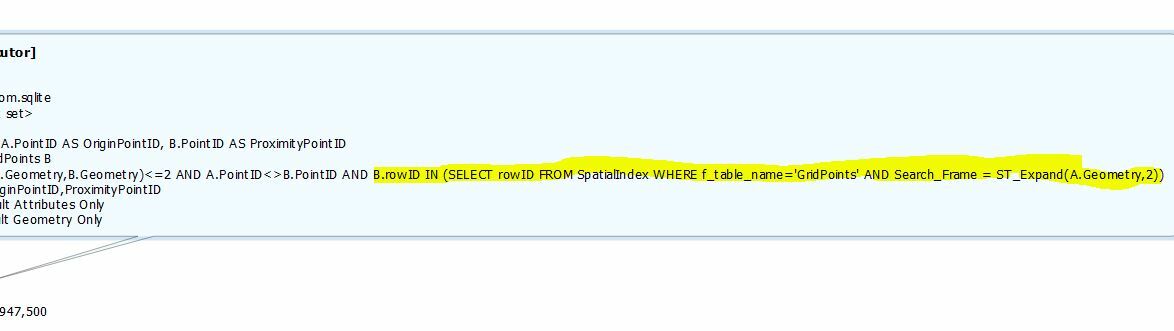
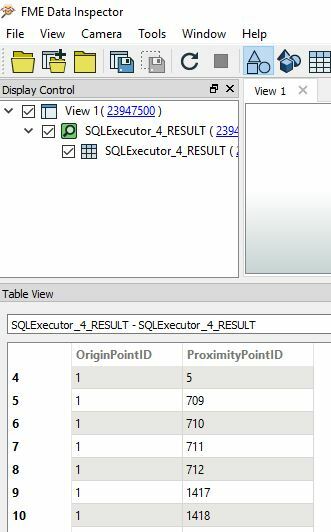
I got a challenge for you: I have 500k+ grid points with a distance of 0.5m and need to find the neighbors from each point within a given radius (let's say 2m).
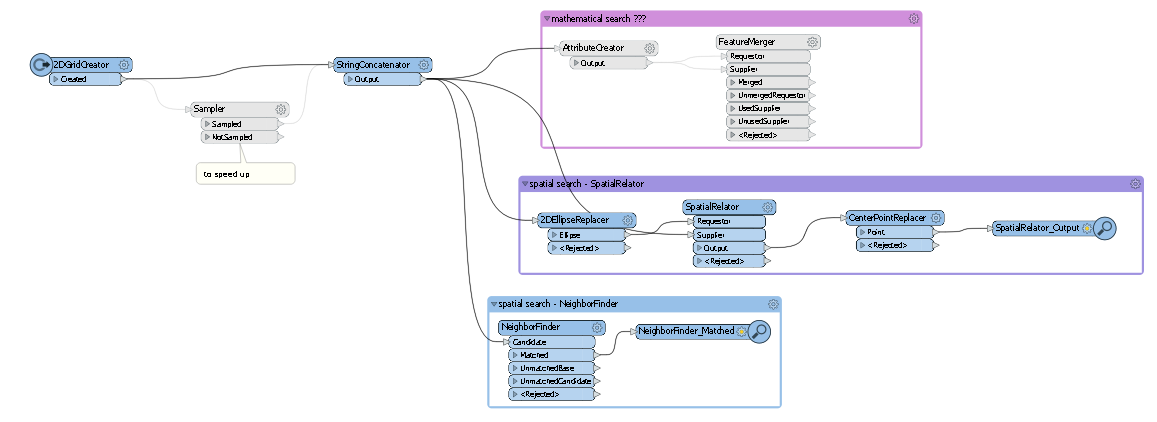
The NeighborFinder takes horribly long. The SpatialRelator has about the same calculation time.
What I am now thinking of is to get the neighbors mathematically rather than spatially. For each point I can create the attributes minX, minY, maxX and maxY. Then, I just need to test if one of the other points' coordinates are greater or smaller, right?!
In the end every point should have a list of all his neighbors (and their attributes).
Any ideas? Or any hints how I can speed up the spatial tester?
Cheers,
Maria