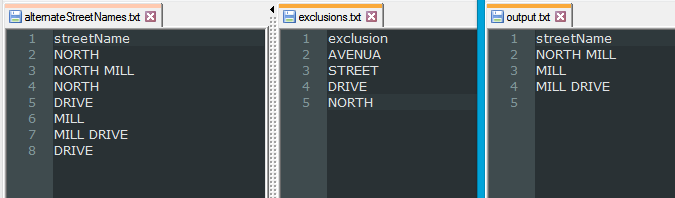
I have a table called "alternate street names" that contains values such as: NORTH, NORTH MILL, NORTH, DRIVE, MILL, MILL DRIVE, DRIVE. (These are the permutations of 'NORTH MILL DRIVE'.)
I also have a table of "exclusions", such as: AVENUE, STREET, DRIVE, NORTH.
The objective is to only write the rows from "alternate street names" where the alternate name is not in "exclusions". Also note that the "exclusions" must be read at run time.
I did a lot of searching and trying different transformers, but could not get anything to work. This seems like a very simple task and I'm just overlooking something.
Best answer by jeroenstiers
Hi t1,
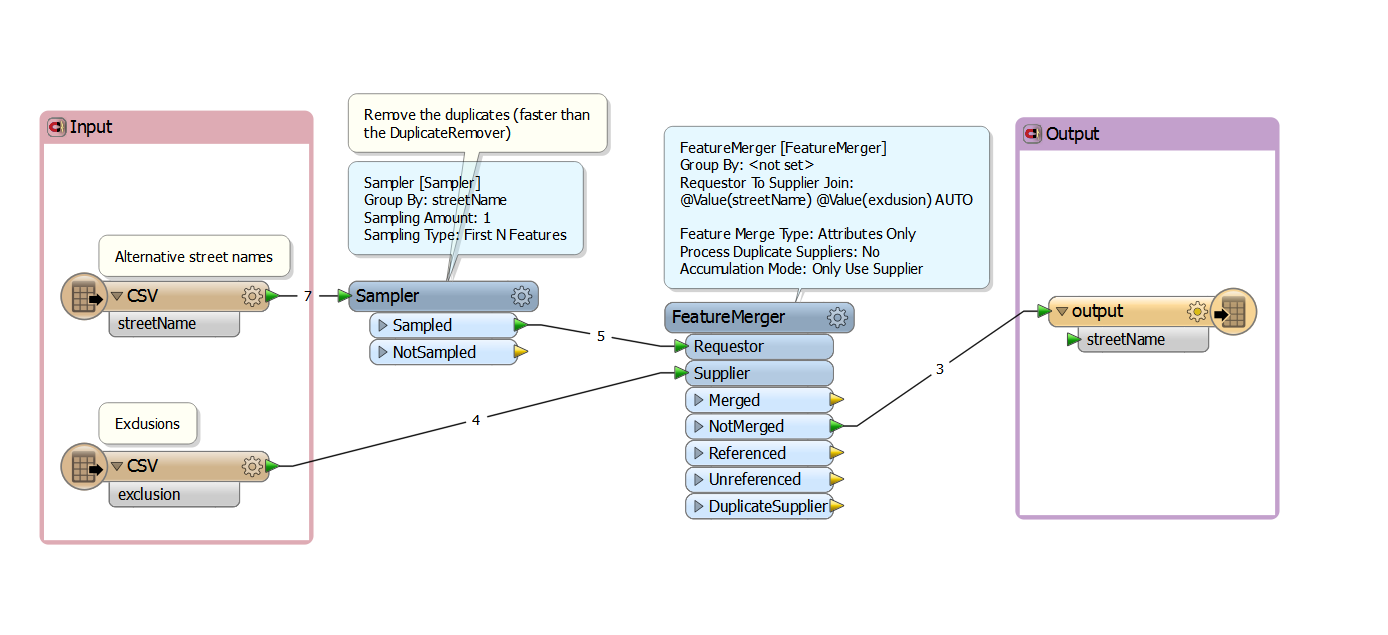
As already mentioned by erik_jan and gio you can use the FeatureMerger to tackle this problem. I noticed that you have duplicates in the list containing the alternative street names. Try to remove those (if that is the functionality you want) before using the FeatureMerger using a sampler with a group by (see screenshot below).
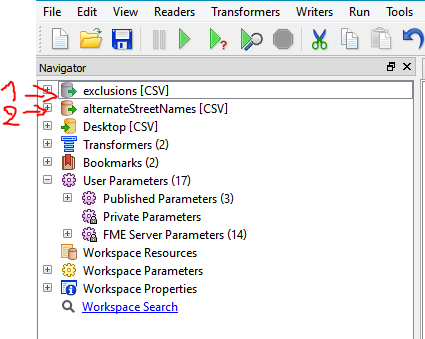
If the list of alternative street names and the exclusions is rather large, you can improve the performance by using the suppliers first-option of the FeatureMerger. But make sure all suppliers arrive before the first requestor! This can be done by reading the data from the exclusions first. Ensure this by dragging this reader on top of the reader reading the street names.
Did this help you find an answer to your question?
This post is closed to further activity.
It may be a question with a best answer, an implemented idea, or just a post needing no comment.
If you have a follow-up or related question, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
If the values you described are attributevalues then you only need touse a featuremerger on the attributevalues from each table.
As featuremerging is almost basic functionality and you said you did a lot of searching, it makes me believe that your table is constructed differently? For onstance you might be naming strings rather then attirbute values?
As already mentioned by erik_jan and gio you can use the FeatureMerger to tackle this problem. I noticed that you have duplicates in the list containing the alternative street names. Try to remove those (if that is the functionality you want) before using the FeatureMerger using a sampler with a group by (see screenshot below).
If the list of alternative street names and the exclusions is rather large, you can improve the performance by using the suppliers first-option of the FeatureMerger. But make sure all suppliers arrive before the first requestor! This can be done by reading the data from the exclusions first. Ensure this by dragging this reader on top of the reader reading the street names.
If the values you described are attributevalues then you only need touse a featuremerger on the attributevalues from each table.
As featuremerging is almost basic functionality and you said you did a lot of searching, it makes me believe that your table is constructed differently? For onstance you might be naming strings rather then attirbute values?
FeatureMerger was one of the first things I tried, but it did not work as expected. It works like a champ now however, and I have no idea what was wrong before. Thanks for your help.
We use 3 different kinds of cookies. You can choose which cookies you want to accept. We need basic cookies to make this site work, therefore these are the minimum you can select. Learn more about our cookies.