Hi,
I have the following scenario:
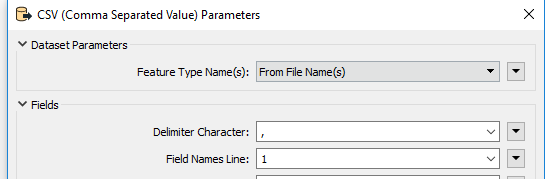
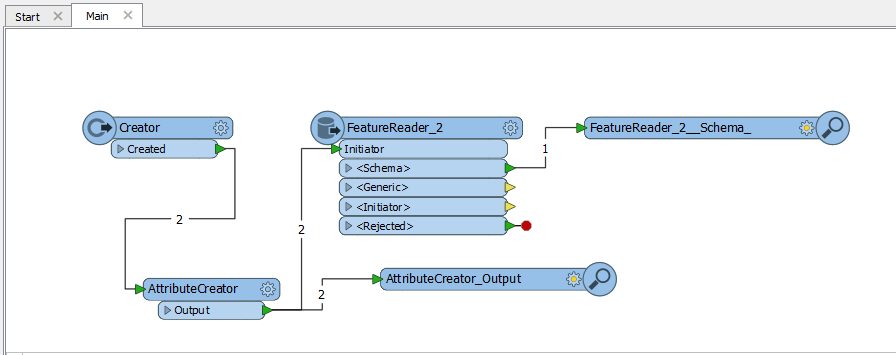
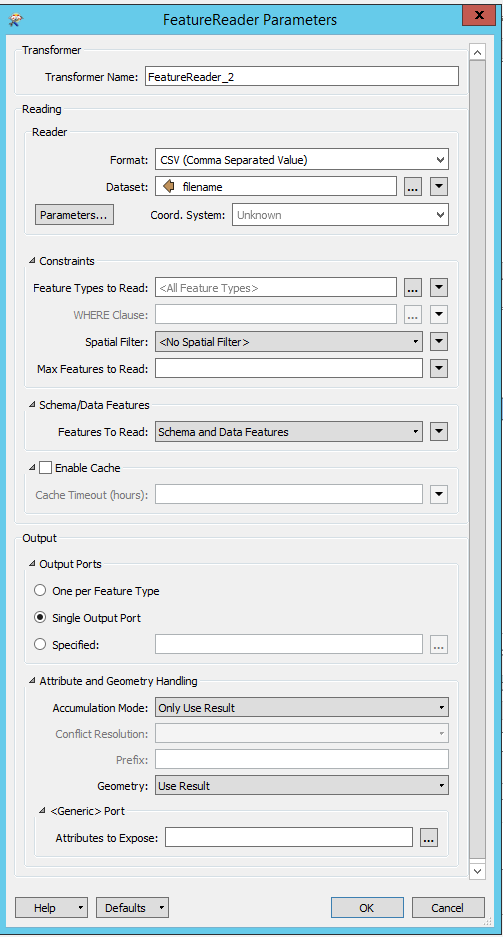
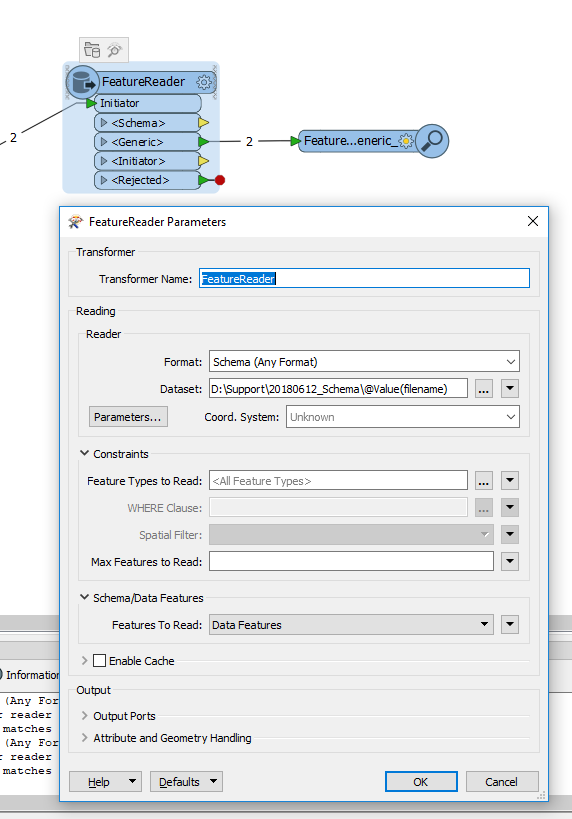
I extract a list of xlsx filenames from a database table and I want to perform a check on their schema (i.e. column names and data types). I feed the output of a database reader to a FeatureReader initiator so that for every input feature a different file is read.
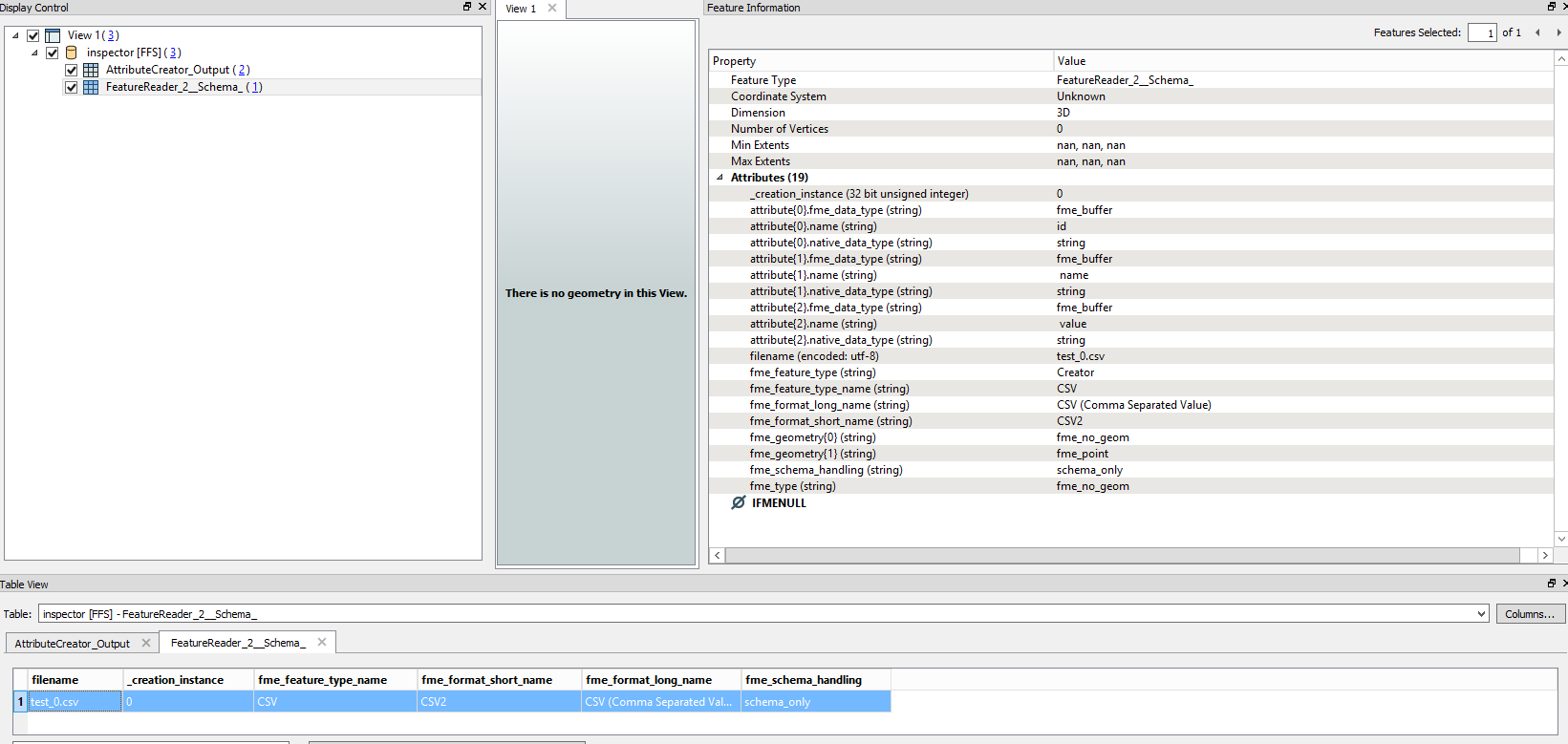
In the FeatureReader I only read the schema. I expected to obtain a different schema for each record of the database but in fact I only get a single schema.
Is there something I am missing?