
Hi all, I'm working on an FME workbench for a client that will be run on their FME Server.
Some background:
- They are running 32-bit Server Engine on a 64-bit Windows box, so I know that it's limited to 4GB RAM
- The datasets we're using are pretty large, with around 3-3.5 million records being read in between the 5 different readers (the largest reader takes in 1.8 million)
- All but 63.5k of the total are Esri point geometries with some attributes
- All datasets must be read in their entirety by nature of the workflow (we can't break it up into smaller datasets with sub callers)
- I have FME_TEMP set to a folder in a drive with 58GB of free space
- Speed is secondary - we need it to run, fast can happen later
- I don't have any user permissions on the FME Server box - I can't edit files, I can't rename files, delete files, move files, NOTHING, so I'll have to pass any recommended changes through my boss who does have full permissions.
I'm getting two major problems (when it's not one, it's the other):
The first and causal error (from what I can gather) is this one: I get the old "Insufficient memory available -- error code was 2 - please read the FME Help section 'Adjusting Memory Resources' for workarounds. " I've already tinkered with the settings of FME_MEMORY_REDLINE to no avail.
As soon as that flashes across the screen and the process terminates, though, I'm unable to make use of the logs. FME Server seems to delete them without backing up once the job fails, so I'm unable to dig in and find more detail. They should be in C:/ProgramData/Safe Software/FME Server/resources/logs/engine/<current or old>/jobs/0... right? I get this error when I try to inspect the logs in the server web view, and that folder is empty when I check after the run:

Here's the really weird thing: I watched that folder mid-run last time, and noticed two strange behaviors.
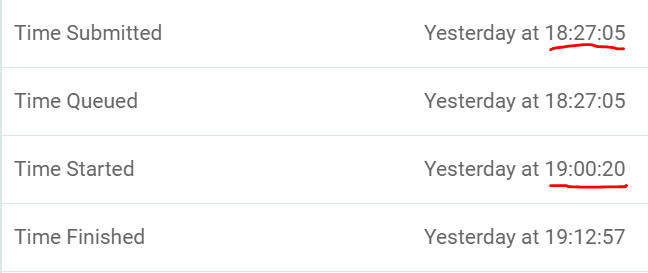
In the FME Server web dashboard, the start time would change every 15 or so minutes, and the log would show what seemed to be the workbench restarting without throwing an error. The only place this is captured is in the status pane, since the log is gone, and it doesn't show that for the first 15 minutes, the start time showed the same as the Submitted time, then updated around 18:45, then updated again at 19:00:
When that change occurred, I got on the FME Server box to check the log folder, and found this (as expected):

Then inside the job_93 folder, there was this:
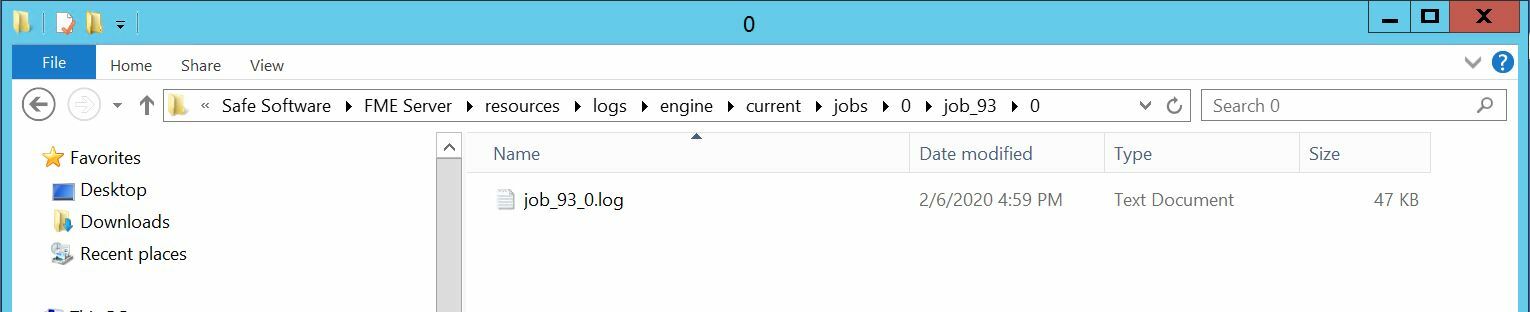
There was a sub folder and another log file during the run, just after the start time change and apparent restart in the log, but when the job terminated (reason unknown, presumably memory issues), it wiped the log without backing up into the /old folder.
I'm unsure how much of this apparent restart/log wiping behavior is some form of expected behavior, but it's making debugging quite difficult.
As for running out of memory, does anyone have advice besides adjusting FME_MEMORY_REDLINE? And, with so much space in the FME_TEMP folder, why is it not caching locally and skipping straight to running out of memory?
UPDATE:
After a call with @hollyatsafe and some others from Safe, we seem to have it working! The issue of logs going missing seems to have been a fluke, and hasn't happened since. Memory issues may still present problems, but we've figured out ways to mitigate that by running spatially clipped subsections of the datasets with feature readers (rather than plain old readers).
I'll resurrect this thread if these issues persist, but for now we seem to have it under control. Thanks to those who posted answers, and to the Safe folks for the direct help!


