I'm trying to extract all of the data from a table that lives on a webpage along with the hyperlinks that are embedded inside of one of the columns. The HTML table reader is only able to return the data that is displayed on the webpage, not the hyperlinks that are present. On the flip side, I can only get the HTMLExtractor transformer to collect the first record in the table. Attached is my workbench... what can I do to collect all of the records in the table?

Solved
Extract table from webpage and hyperlinks in table
Best answer by caracadrian
@Chris Warren You are on the right track.
By modifying your workspace a bit you can obtain the desired result.
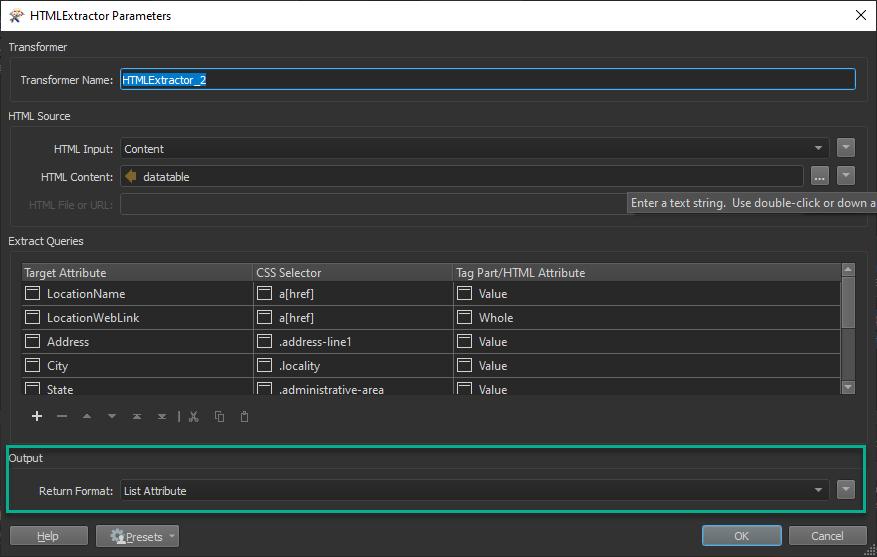
Set your second HTMLExtractor to Output: Return List Attribute
Add ListExploders for every list that you need than merge the list via FeatureMerger using one of them as a Requestor and the rest as Suppliers, Join On _element_index, set it to Process Duplicate Suppliers.
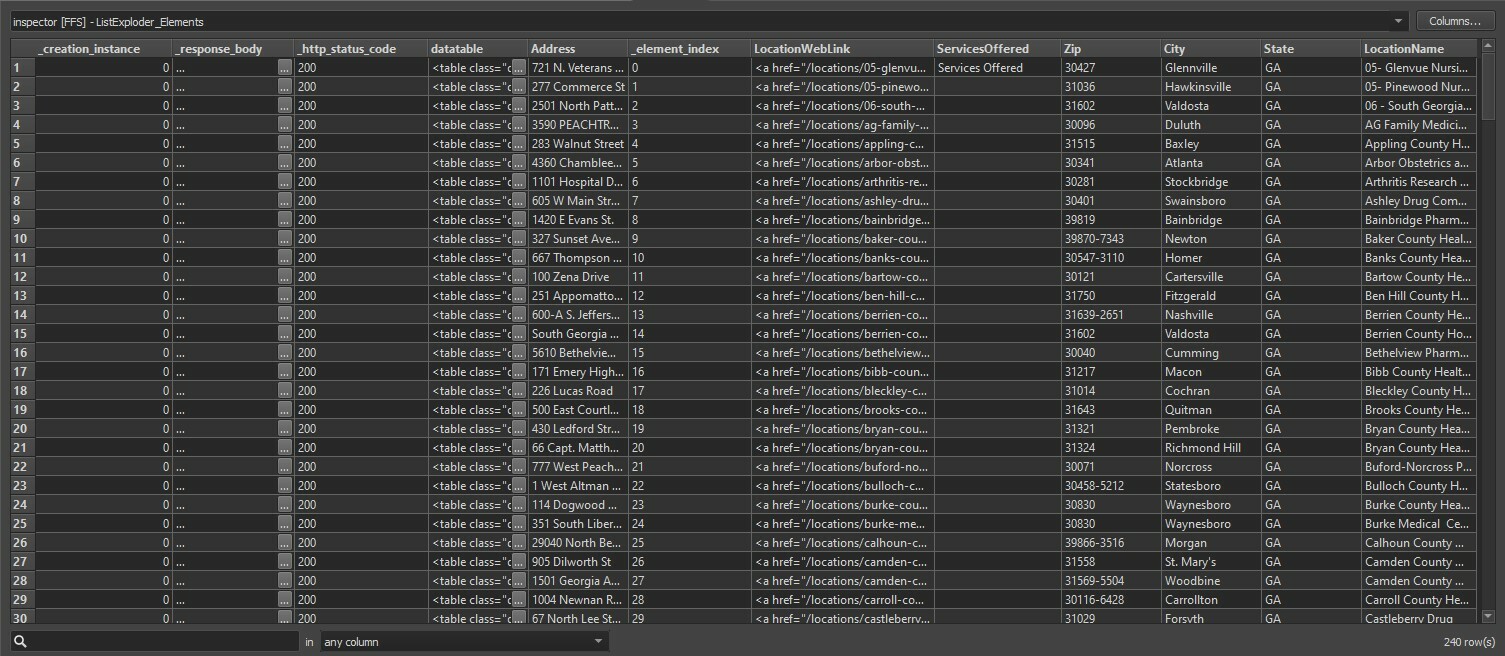
Than you can continue to your Attribute Splitter.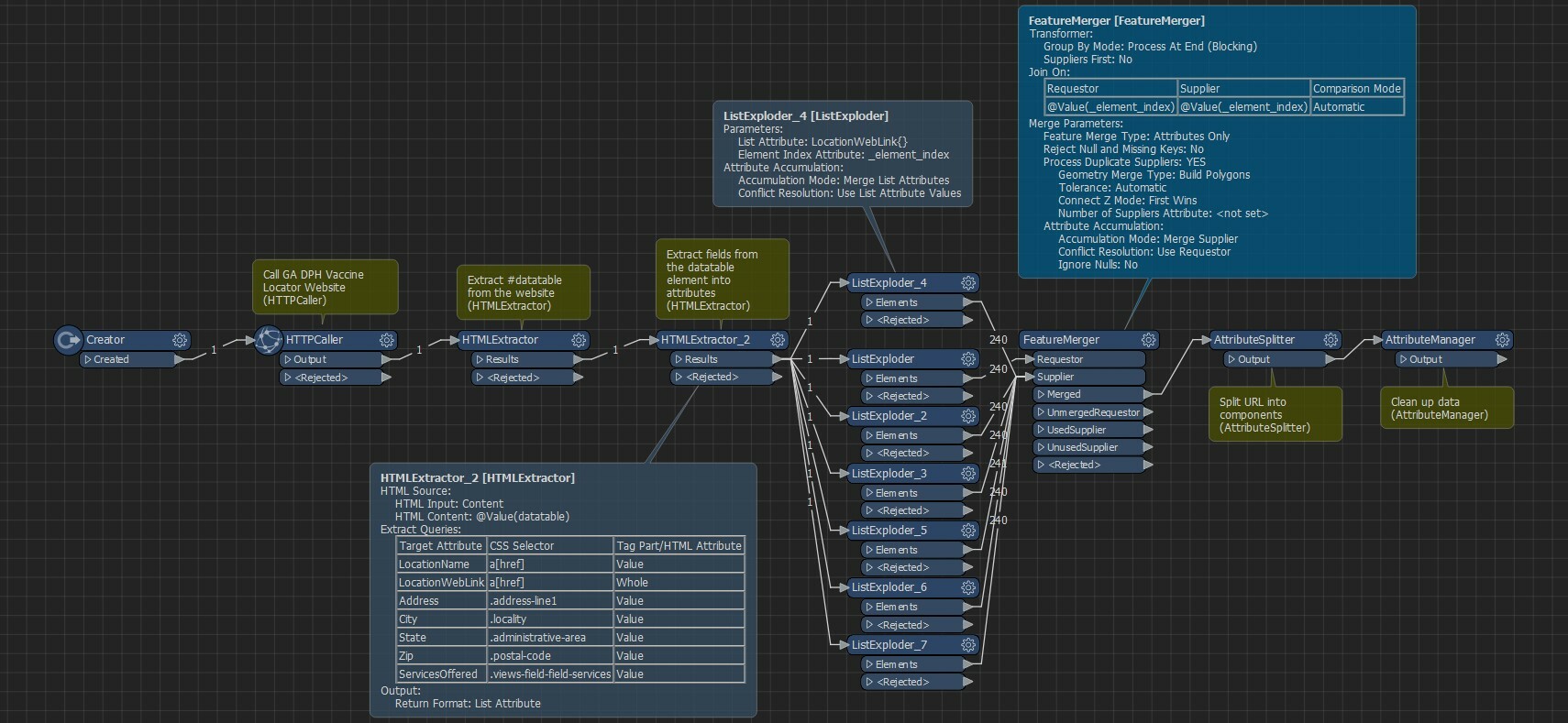 By setting a ListExploder for every list you can obtain something like this:
By setting a ListExploder for every list you can obtain something like this:
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.






Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.