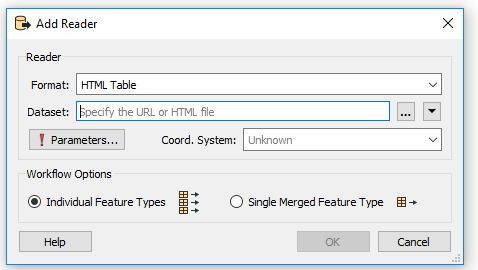
Hello all,
I'm try to extract a information from Webpage using the transformer HTMLExtractor, but i didn't a good result.
The Website is http://www.brasil.gov.br/ and the important information for me to extract is the href from this part of page:
Fale com o Governo
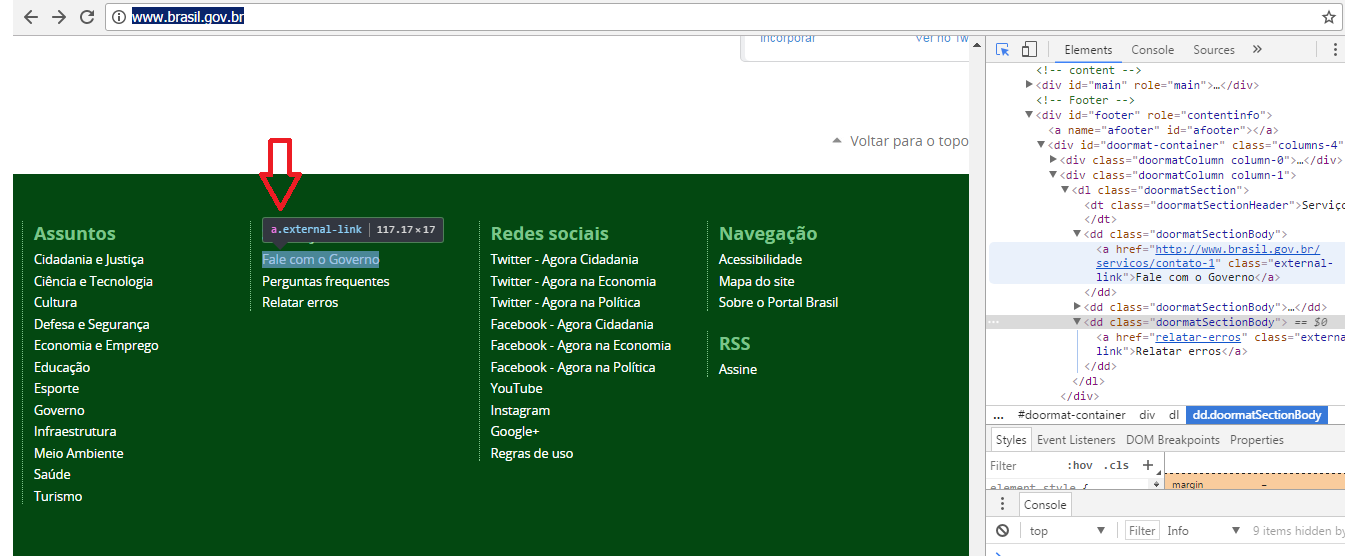
Attached my template file.
Thanks in Advance,
Danilo de Lima