
Hi, I would like to extract data from a web page coded. I already get the password. The url is :https://www.portail-nextgen-telecom.tdf.fr. I need to read the url , find the data : Document Contractuel. Read it. If there is a value , get it. i tried with htlm extractor but the response is a script. I need a value. yes or no the Document contractuel is here. Anyone can help me ? 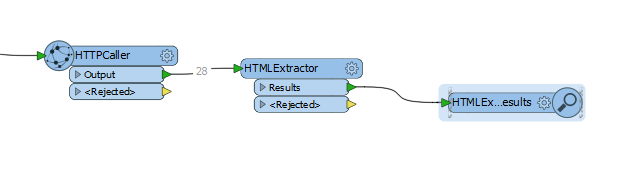

Question
Extract data from a web page
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.


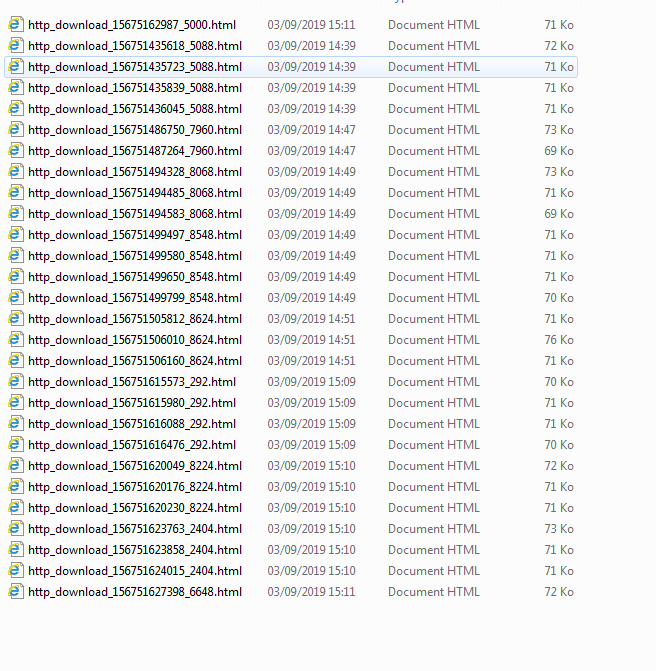 Now I want to extract the file name : Document Contractuel, from these htmls.
Now I want to extract the file name : Document Contractuel, from these htmls. 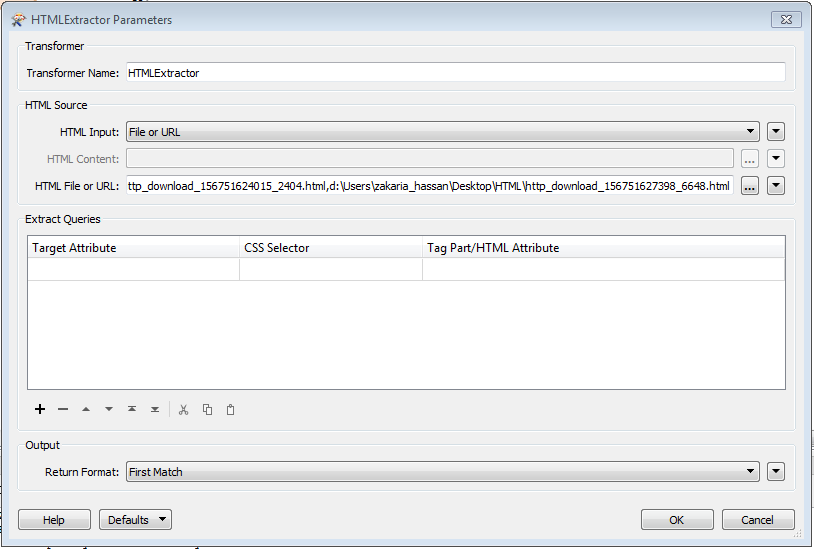
 The file that I want to extract is : DC_POUR_VALIDATION...docx. But the probleme is that the file is located behind an attribute : TYPE. So , what should I do to only extract this document?
The file that I want to extract is : DC_POUR_VALIDATION...docx. But the probleme is that the file is located behind an attribute : TYPE. So , what should I do to only extract this document? Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.