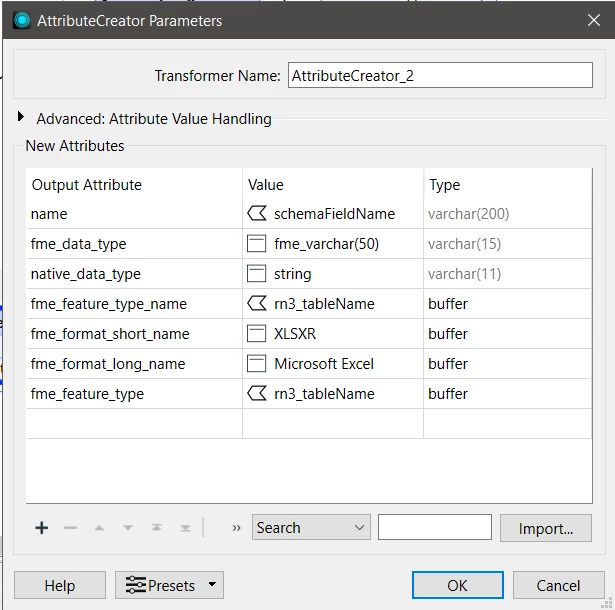
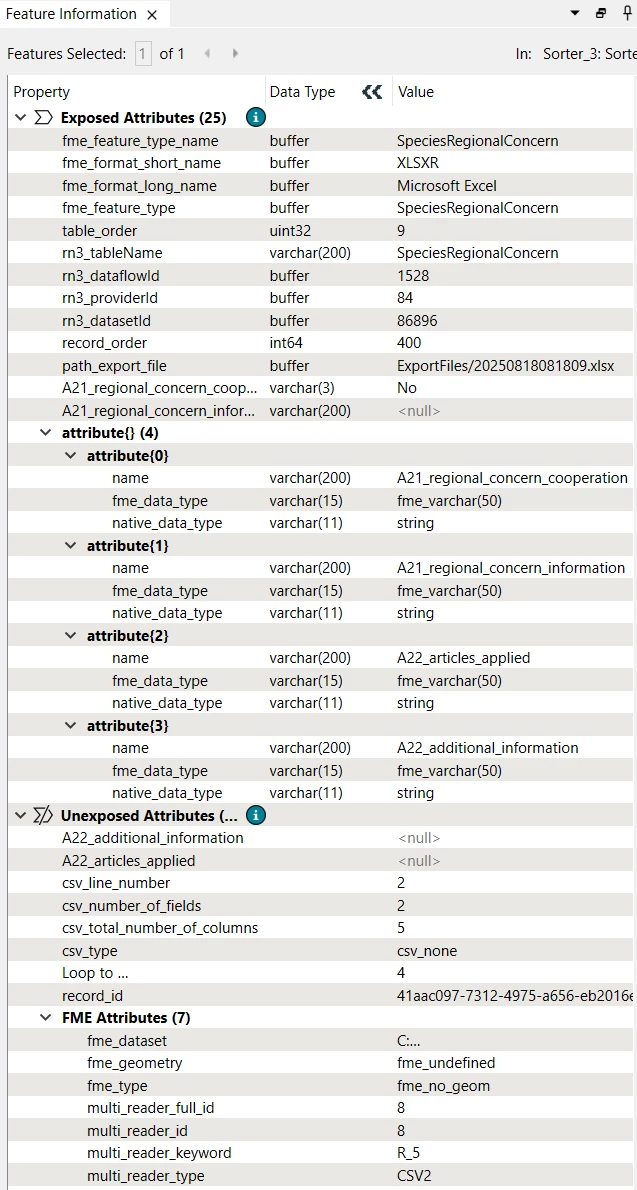
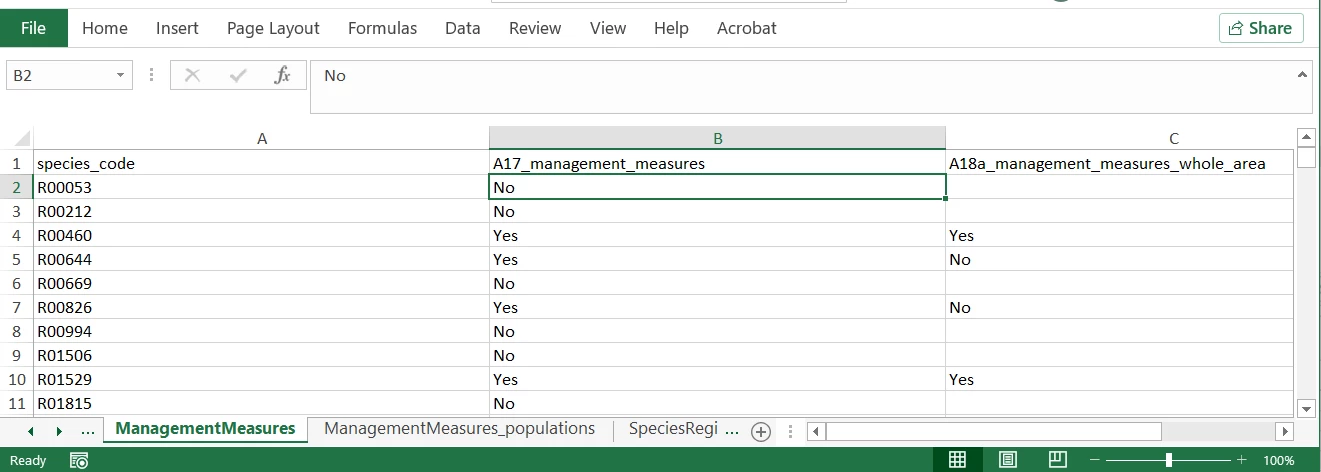
I’m using FeatureWriter to write data using dynamic schemas to multiple worksheets of an Excel file.
In the particular case where I detected the issue, the data meant for the last worksheet contain just one row and value in just one of the columns. This value is ‘No’.
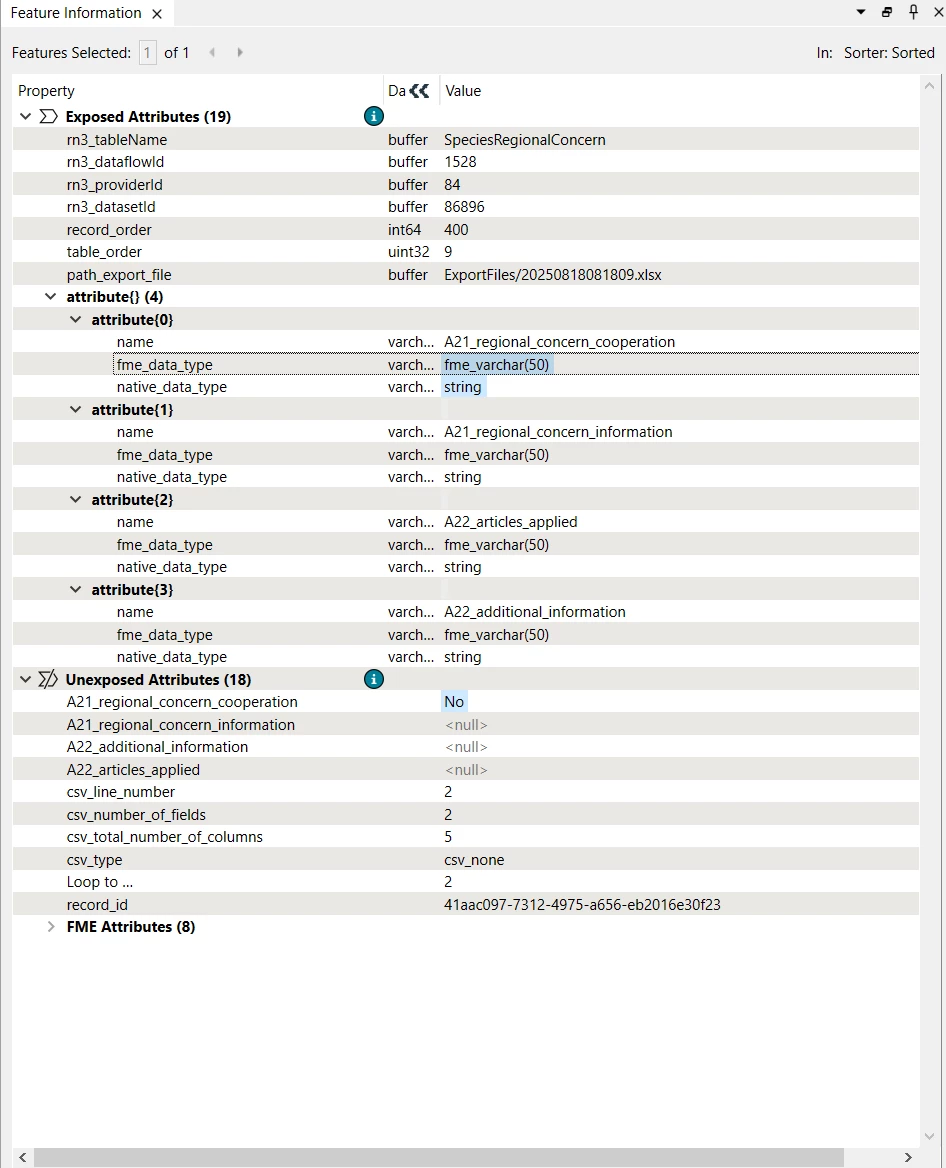
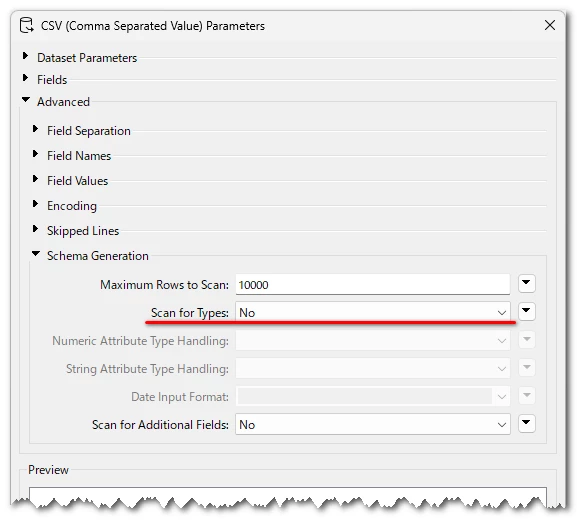
As you can see, the native_data_type of the respective schema attribute for this value is ‘string’.
In the result excel file, however, the ‘No’ value is changed to FALSE.
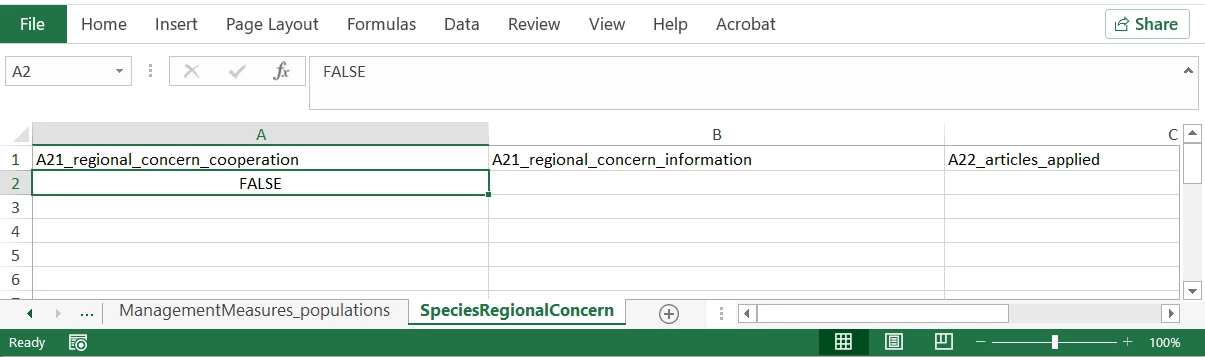
I can’t figure out why this happens.
The Writer writes other ‘No’ values to other worksheets and all of them appear to written correctly as ‘No’.
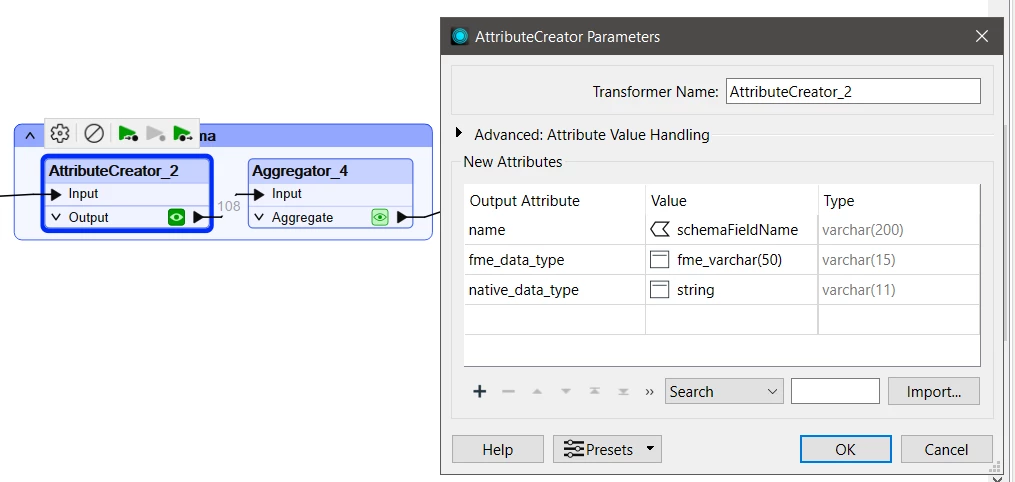
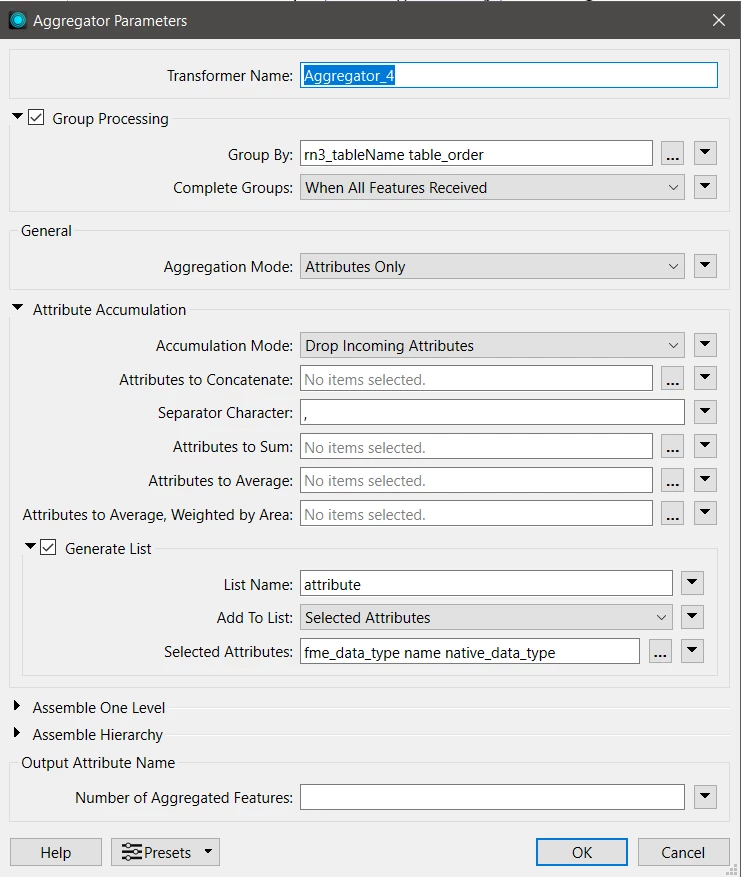
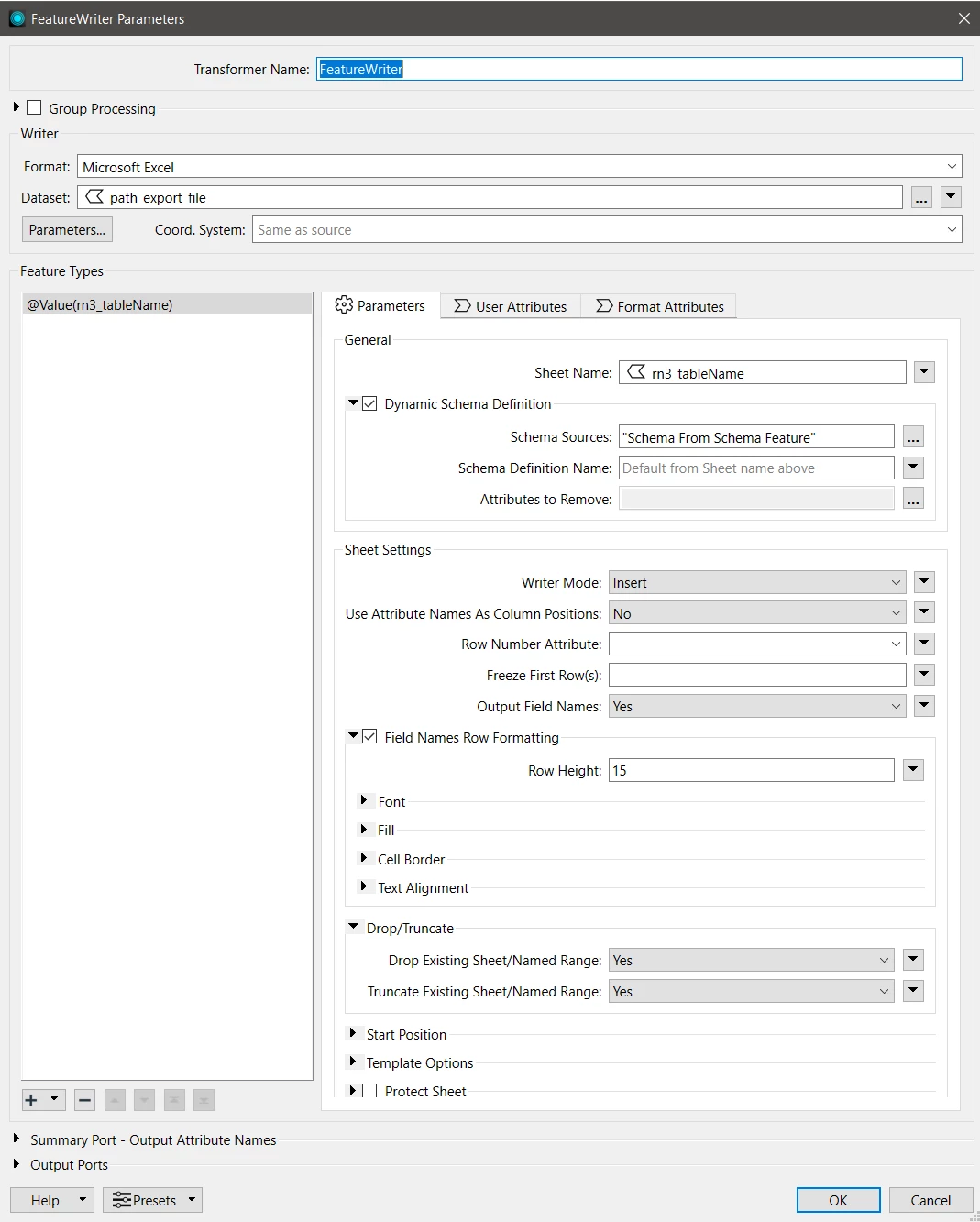
This is the FeatureWriter setup:
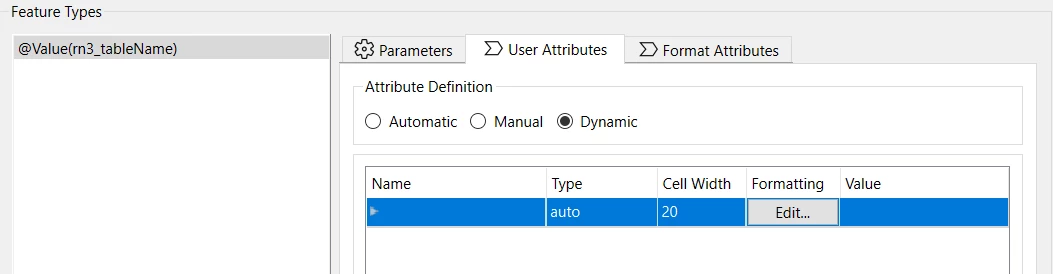
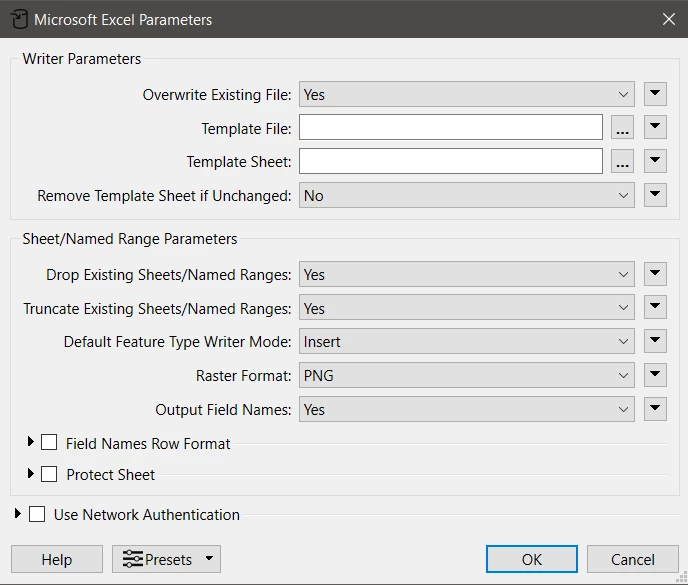
Have I made a mistake somewhere, or is it a bug in the Excel Writer?