I have a simple workbench consisting of a FeatureReader, a VertexCreator and a FeatureWriter writing to a postGIS table. I am reading an Excel spreadsheet.
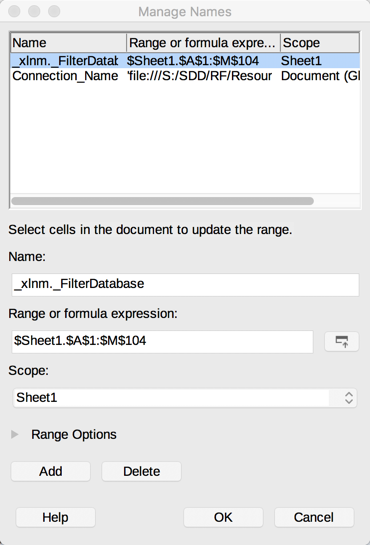
The problem is that the FeatureReader is reading an extra row beyond the data and passing null coordinates into the VertexCreator. I have 103 records, but for some reason it is reading 104. The columns in the last row are all marked as missing. I have checked to see if there is any spurious data, like white space in the last row that might be getting registered as data, but I can't find anything.