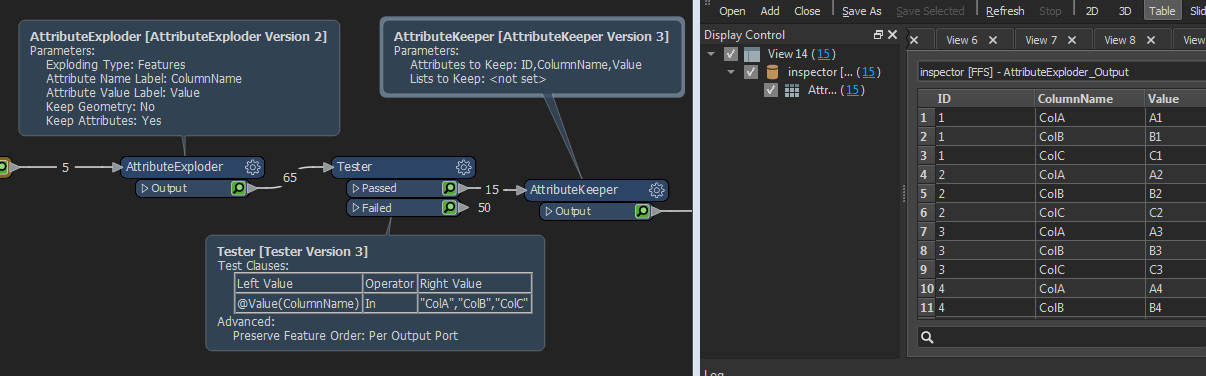
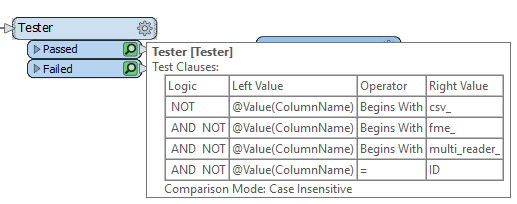
I am new to FME and I wish to make the following transformation.
From:
IDColAColBColC1A1B1C12A2B2C23A3B3C34A4B4C45A5B5C5
To:
IDColumnNameValue1ColAA11ColBB11ColCC12ColAA22ColBB22ColCC23ColAA33ColBB33ColCC34ColAA44ColBB44ColCC45ColAA55ColBB55ColCC5
Can anyone help me out?