Hi,
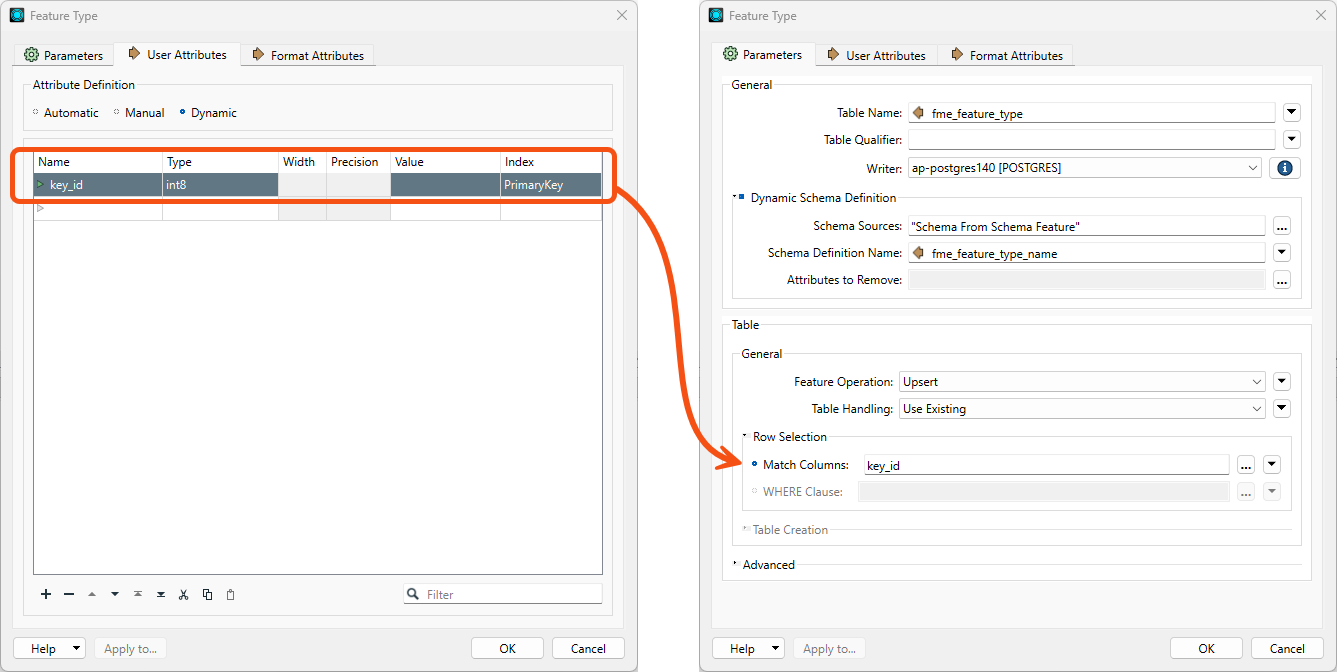
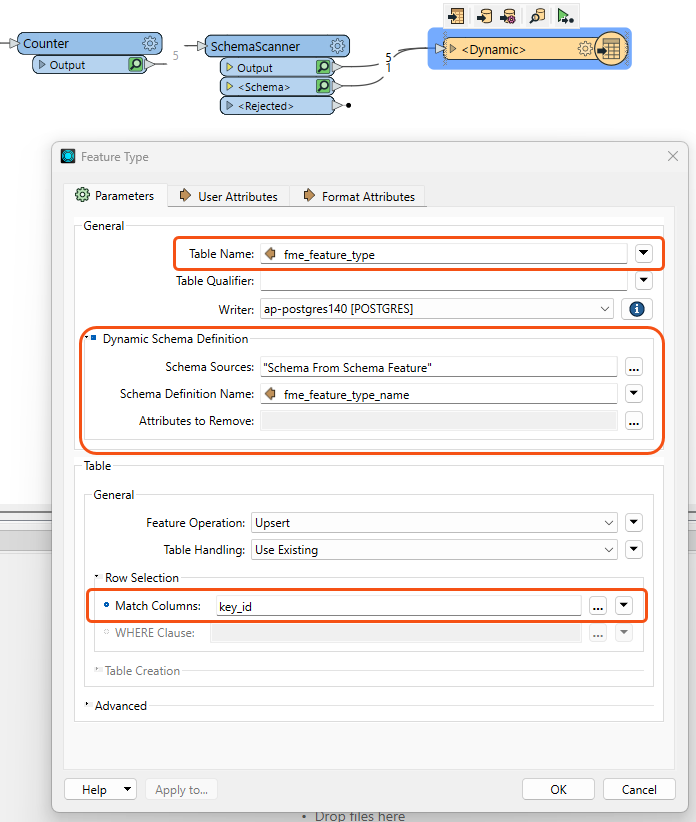
I have a dynamic workspace where I am reading in multiple csv update files for multiple feature types to upsert into our database. I had set the primary key dynamically dependent on the target table in the database. I cannot set a where clause on an UPSERT (which I do use with other feature types that have the ability to do I, U, or D) so went to use the "Row Selection: Columns:" section instead. This parameter does not work in the normal way with attributes. It presumes the selected attribute is the primary key field (no orange left arrow in front of the name), rather than using the value. I tried manually adding @Value(primary_key) (the attribute that stores the primary key column name) in the parameter but the feature writer also presumes it is literal and obviously can't find a column called "@Value(primary_key)" and errors.
This is something that I would like to do, and is very much a part of a dynamic workflow. Otherwise I will have to create one dynamic feature writer for each feature type so I can manually set the primary key column - negating the efficiency of using the dynamic workflow. I can see that FME 2023.1 works in the same way as 2022.2.0 (which is what I am working in at the moment.
Is this something that will come in in the future? Should I add it to the Ideas?