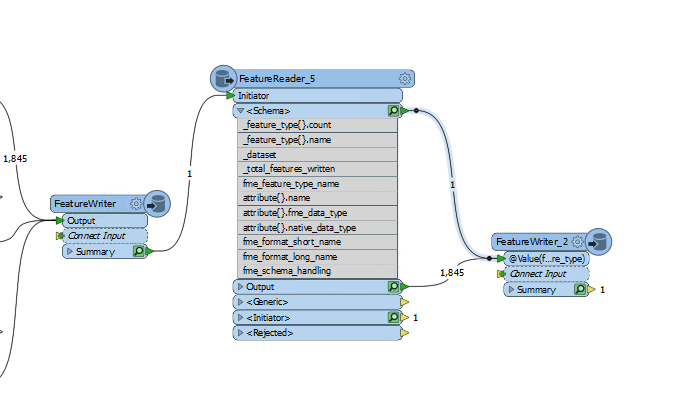
Hi,
I am picking up some JSON from a feature reader and outputting to Excel. It works fine but I would like to order the Excel output so that some header fields are always returned first, e,g, ID, Name, Country
The trouble is that this JSON is dynamic and sometimes doesnt include the attribute 'Country' if it hasn't been populated. This means when the JSON gets brought in and the first record doesnt contain country then it would look structure like so:
ID, NAME, FieldA, Country
Is there any way I can partially define the schema whilst leaving the rest dynamic?
Thank you
Oliver