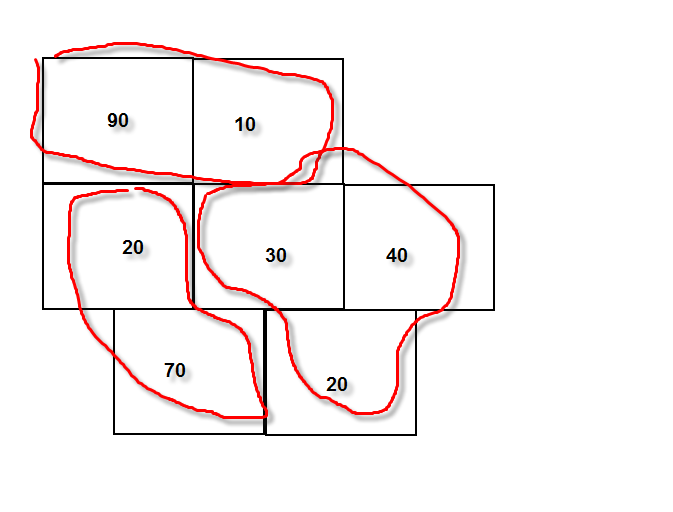
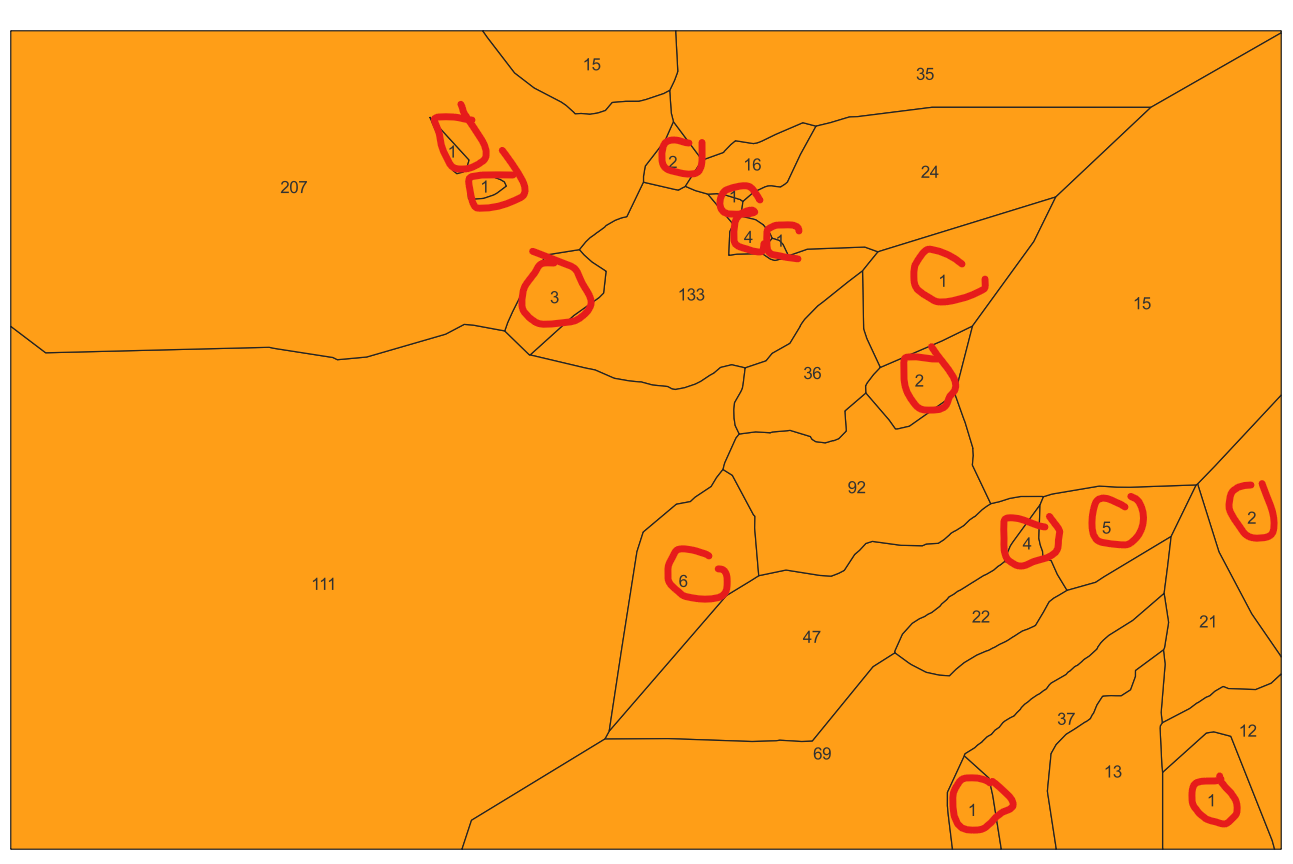
Hi all, I have a situation where I want to dissolve adjacent tile polygons based on a count value. For the example below I would expect the total sum to be no more than 100. Less is fine. The less polygons I end up with the better, but optimization (doing several passes) to figure out the best possible result is not that important. It's sufficient to start from one corner and simply add until all polygons have been dissolved. Also there could be a situation where the polygon has a larger count (110 for example) than expected. In such a case it would be left single - as it is.
So any ideas on the simplest approach in doing this? I expect some kind of loop function in needed. Not very familiar yet with those...
Thanks for any advice!
Attached is an example shape file to play with...