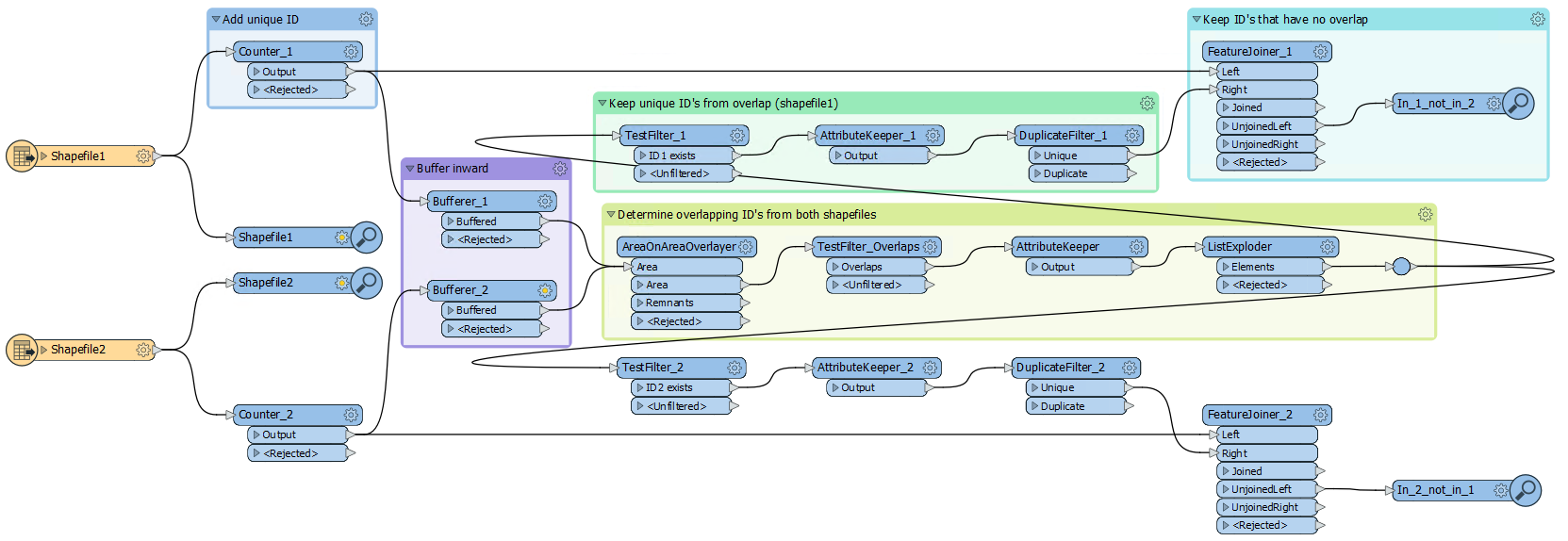
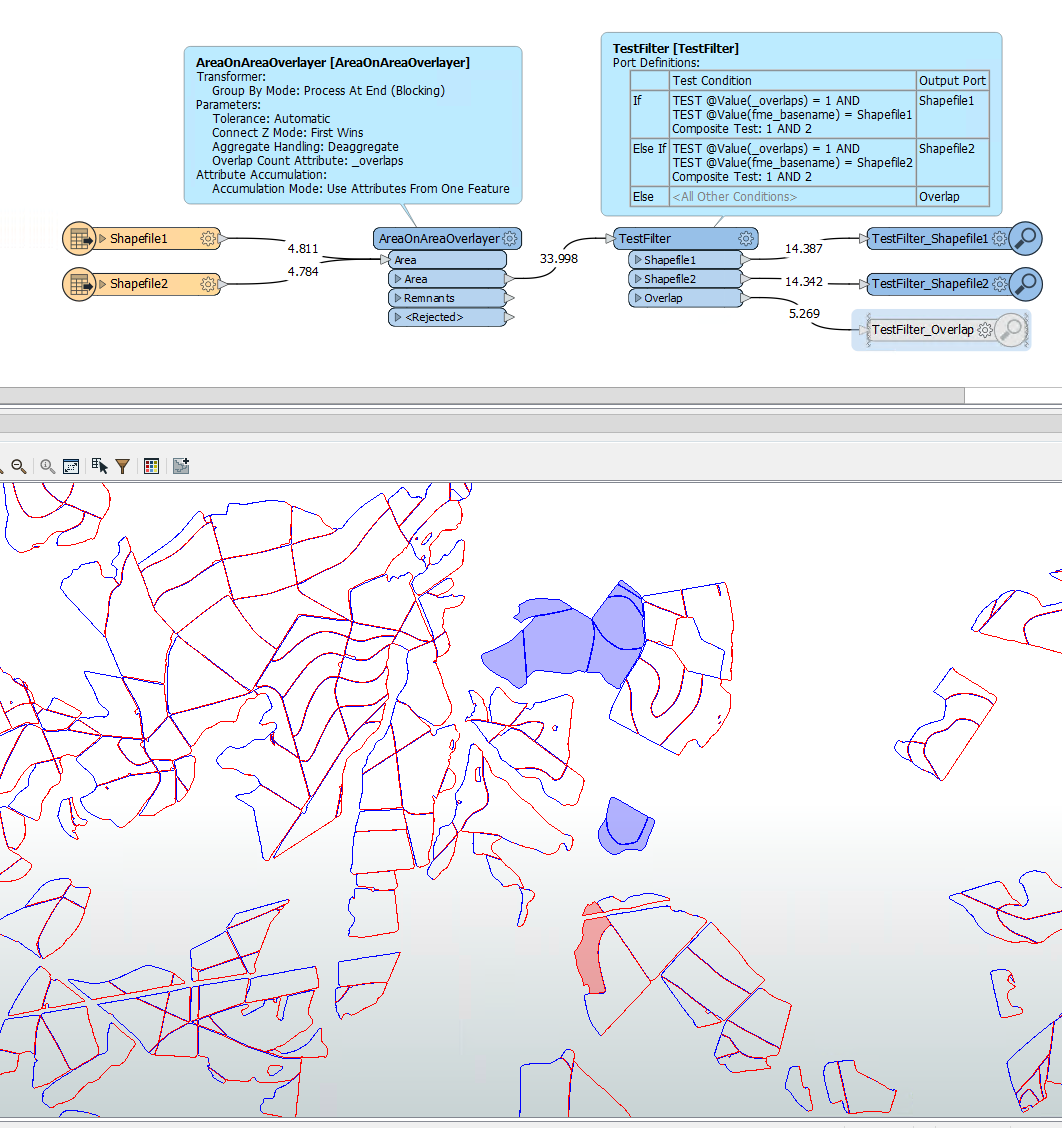
Hi,
Attached I have two sets of data with several polygons. The two are almost identical, but one has different polygons or more polygons than the other. How can I do it using FME? I already used the Spatial Relator transformer and change detector transformer but the results were not good.
I want to know the difference between the two, that is what appeared in one and what disappeared in the other. can anybody help me?
Thanks