Hi,
I need to compare data from an Oracle Spatial database and from an ArcSDE Geodatabase (with an underlying Oracle database). I carry out the comparison of the data from these two sources in FME using the ChangeDetector. Since FME treats dates between the reader and writer as strings, I have the following issues in ChangeDetector:
DateOracle SpatialArcSDE31/12/2011 00:00:00311220110000003112201131/12/2011 03:27:303112201103273031122011032730In the table above you see that when the time is 00:00:00, the date from ArcSDE is a string without the time. The Oracle Spatial reader, however, builds a string that includes the time. When the time is something other than 00:00:00, there is no difference between Oracle Spatial and ArcSDE. As a consequence, ChangeDetector will report changes even for identical data because the date-strings can be different.
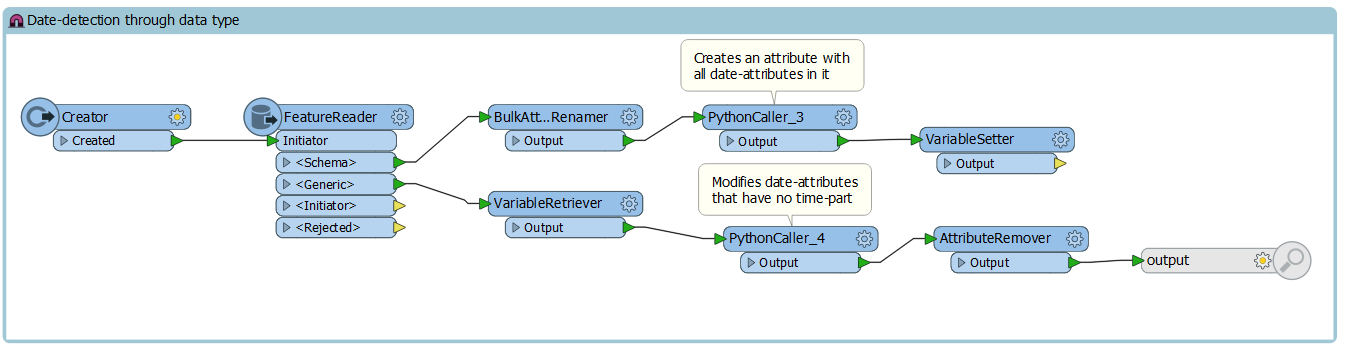
Since the Workspace is generic and used for a lot of different feature classes, a DateFormatter does not seem to be the solution for me. If I want to modify the date-attributes before the ChangeDetector reads them, I will probably have to use PythonCaller and detect the concerned attributes through their name ("contains 'DATE'", not really reliable) or their data type (by using a FeatureReader and merge the schema through FeatureMerger).
However, as the PythonCaller-code could slow down the processing significantly, I wanted to ask whether there is another "FME standard way" of dealing with or avoiding this date-issue.
Greetings,
André