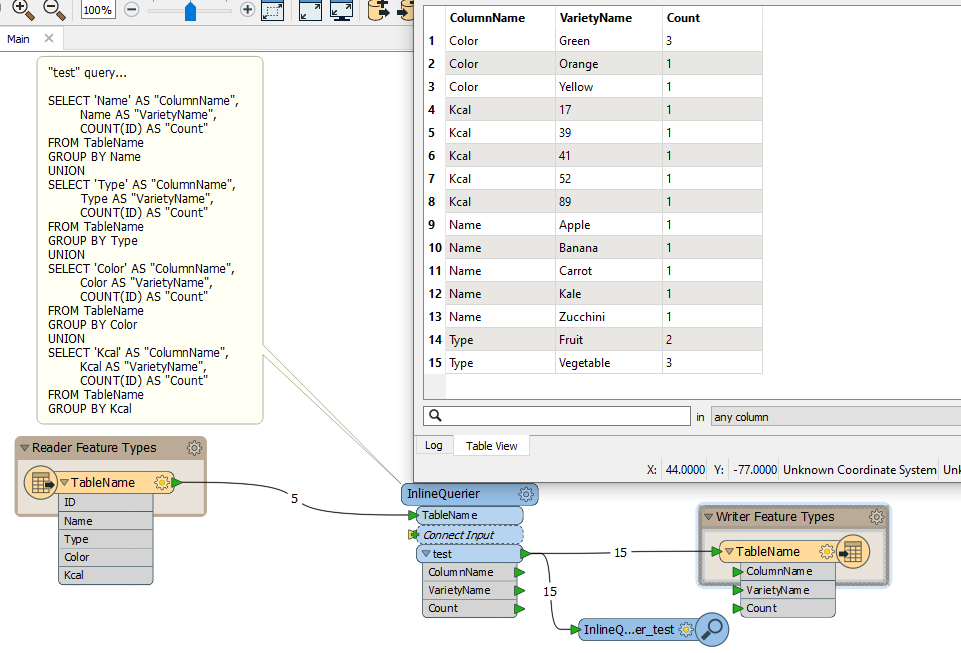
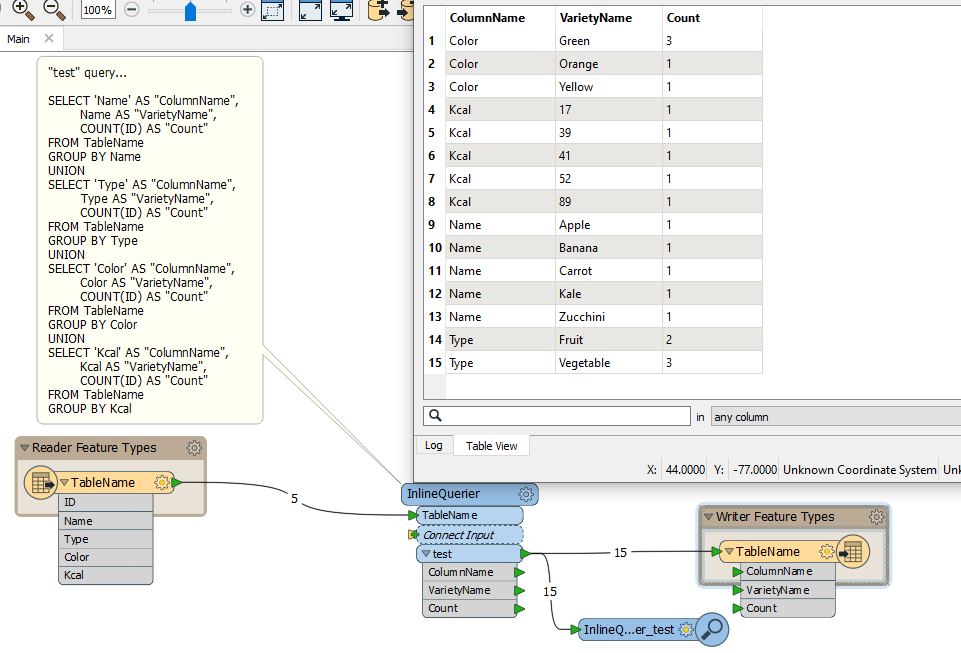
The starting point for my question is a table containing information about fruits and vegetables:
IDNameTypeColorKcal1AppleFruitGreen522BananaFruitYellow893CarrotVegetableOrange414KaleVegetableGreen395ZucchiniVegetableGreen17
I would like to use FME to list all distinct values per column, including a count per distinct value, such as:
ColumnNameVarietyNameCountNameApple1NameBanana1NameCarrot1NameKale1NameZucchini1TypeFruit2TypeVegetable3ColorGreen3ColorYellow1ColorOrange1Kcal521Kcal891Kcal411Kcal391Kcal171
I was considering to use an AttributeExploder to list all columns in separate rows, followed by a StatisticsCalculator to determine the count per variety. However, that seems to consume a lot of time for larger datasets (containing over 1.000.000 records).
Does anyone have suggestions how to accomplish the above result in a better fashion?
")

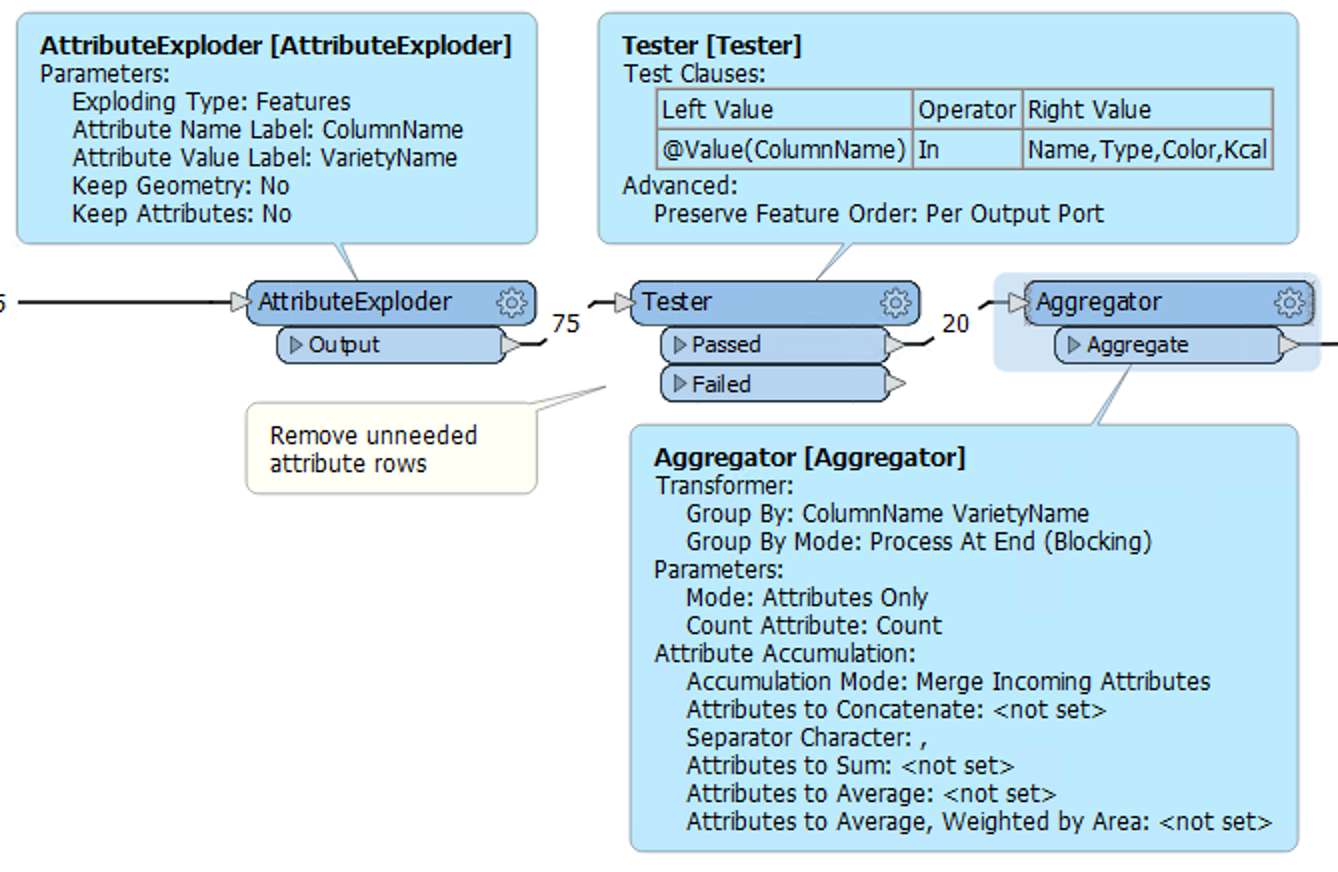
")