Hi All,
I have a survey asking participants to rank their favourite colours—Red, Blue, and Green—in numerical order (1, 2, 3).
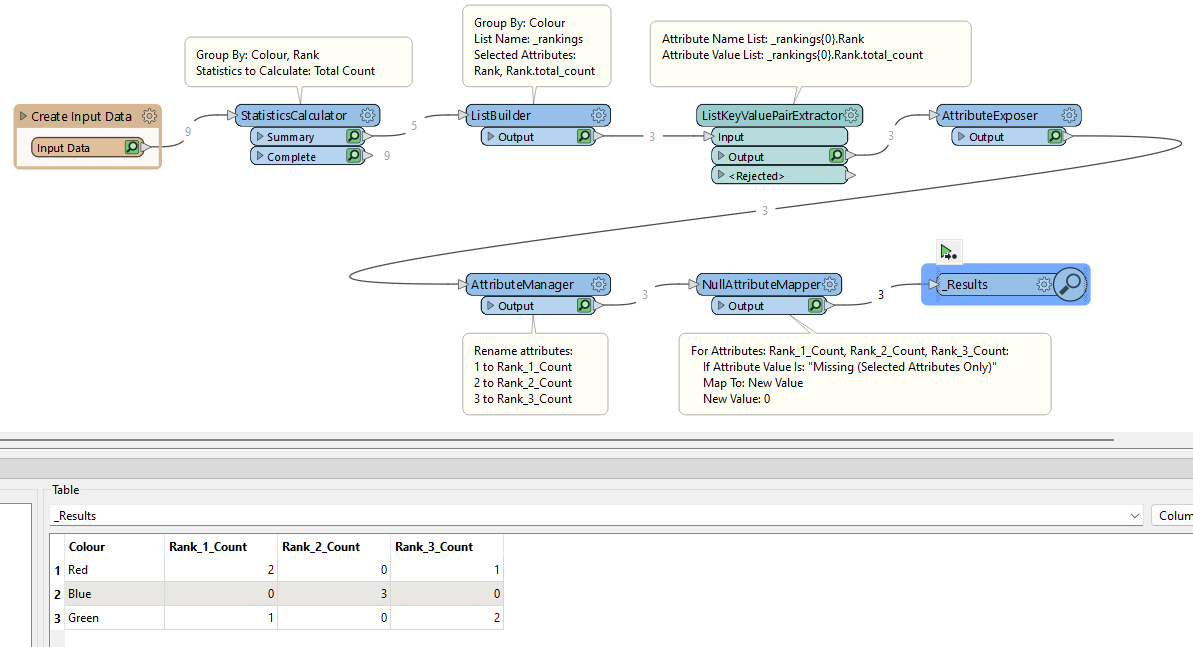
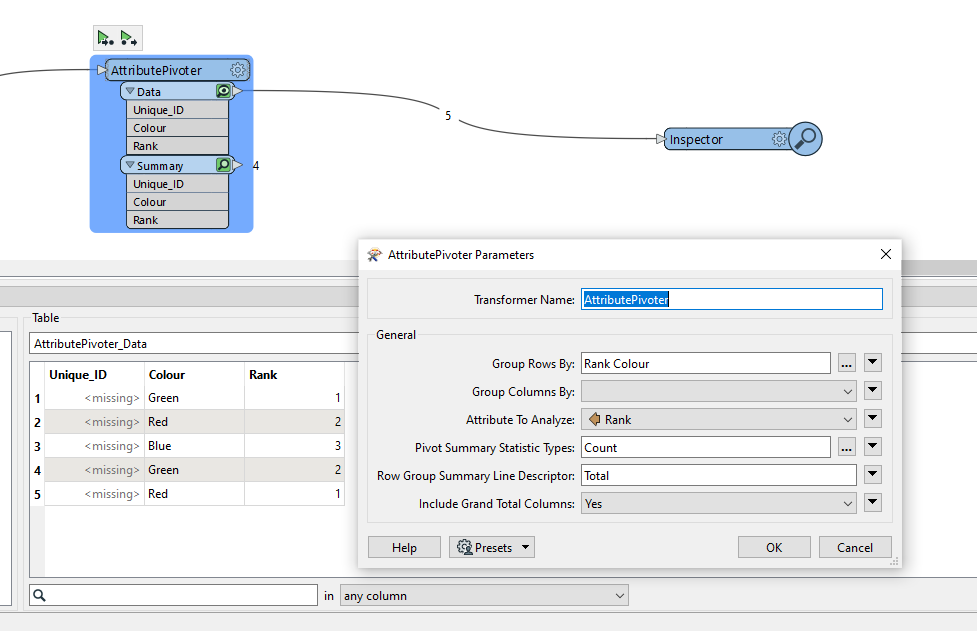
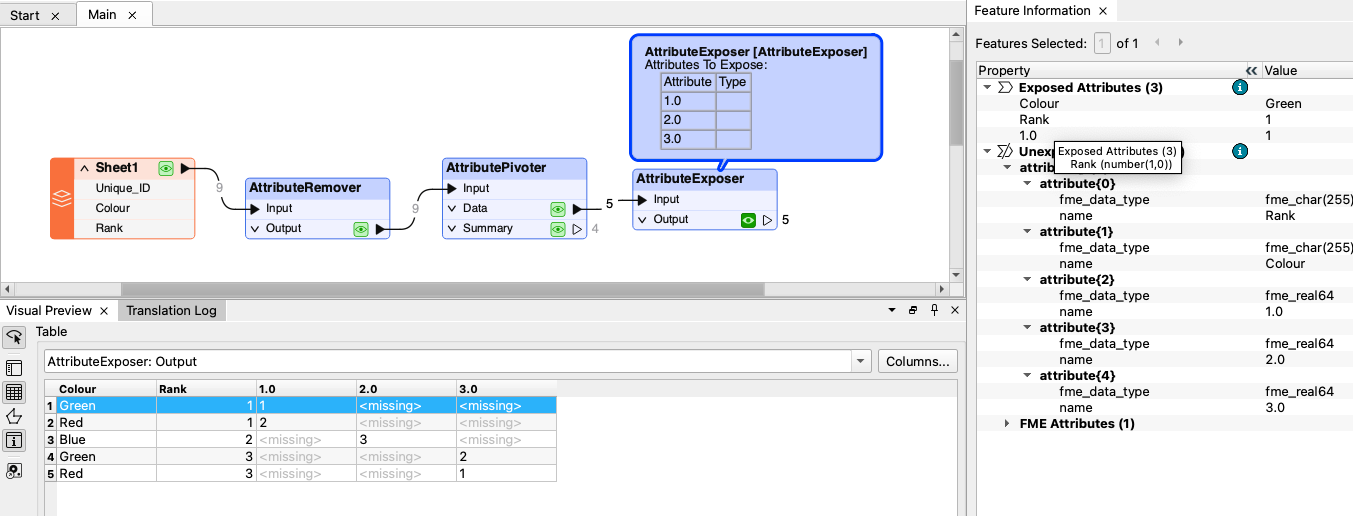
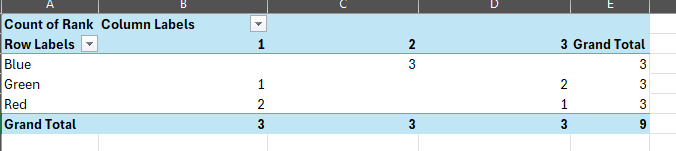
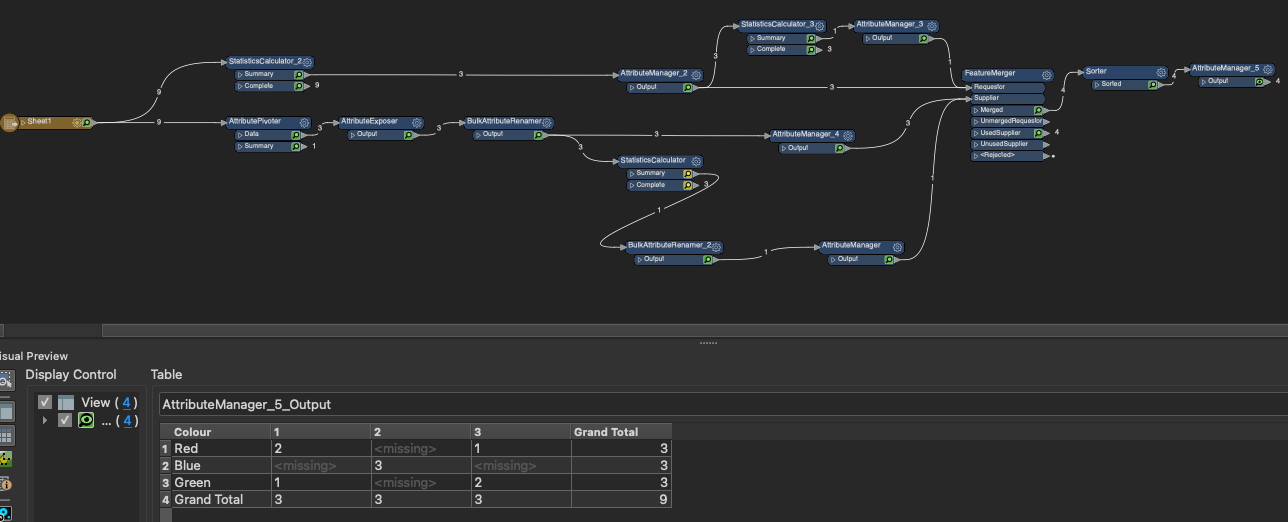
I want to use the results to create a workflow that counts how many times each colour has been picked based on the ranking.
Here is some example data.
| Sample Data | ||
| Unique_ID | Colour | Rank |
| 1 | Red | 3 |
| 1 | Blue | 2 |
| 1 | Green | 1 |
| 2 | Red | 1 |
| 2 | Blue | 2 |
| 2 | Green | 3 |
| 3 | Red | 1 |
| 3 | Blue | 2 |
| 3 | Green | 3 |
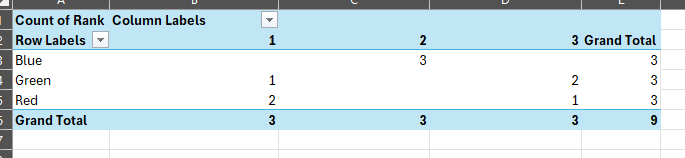
| What I am trying to achieve | |||
| Colour | Rank_ 1_Count | Rank_2_Count | Rank _3_Count |
| Red | 2 | 0 | 1 |
| Blue | 0 | 3 | 0 |
| Green | 1 | 0 | 2 |