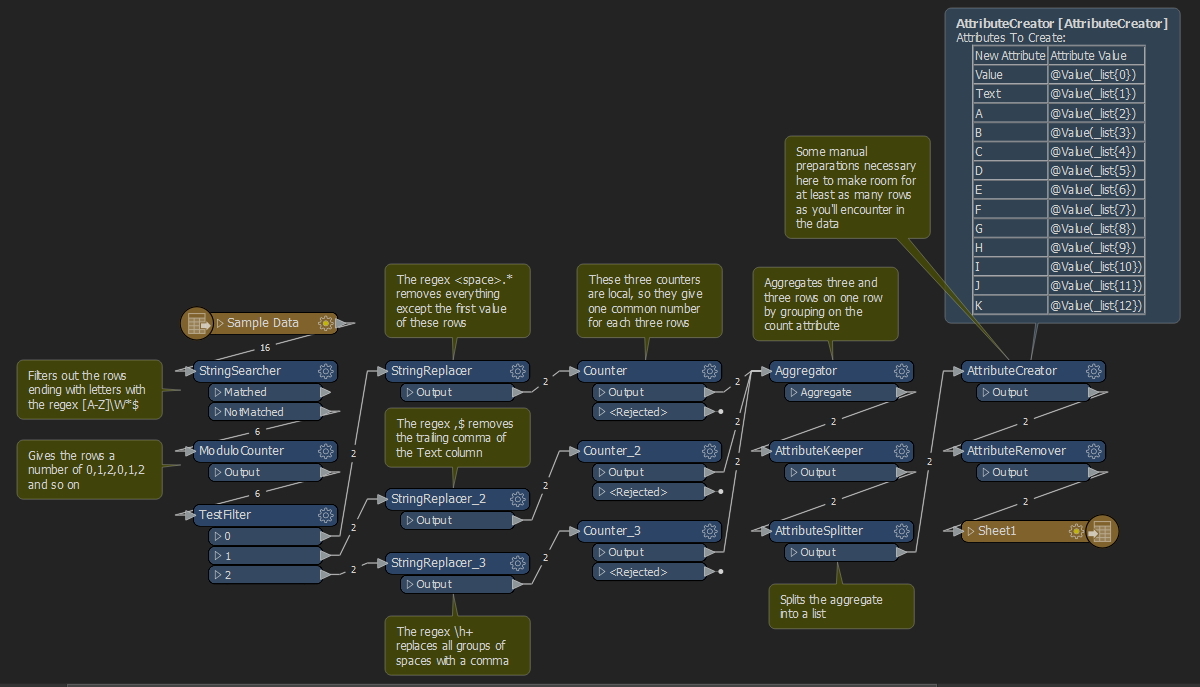
Hi All,
I have my data in the form given below. The data from 1507 to 2451 is a header and the three rows highlighted in green are one set of data and another set is appearing below it with differing values.

Now i want to have the data in the format:
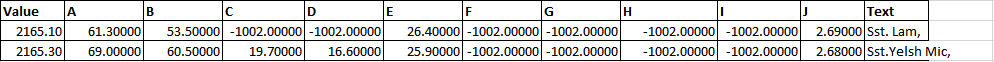
where A to J are my columns names from the header (A-J may change in number like sometimes A-F or A-I or A-J as well). Value is coming from first row of the set of data and text from the third row of the set of data.
Sometimes the data may be missing also. e.g the second row may be missing and only two rows are there. so for that value we have to write nothing in the main table (shown above)
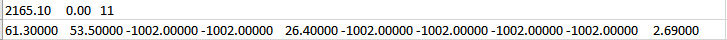
I have attached the excel file for reference
Kindly help.