
Hello guys,
This is my first FME script
I am trying to convert new JEPGS in a folder
to PDF
how do I do that ?
what transformers and how to is et my readers and writer to be taking all the new JPEGs and converting them into PDFs with the same names ?


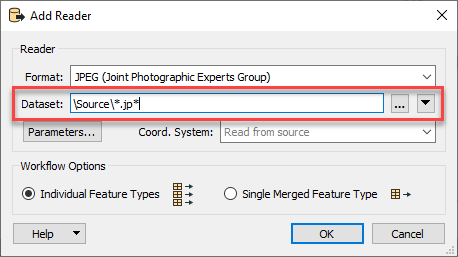 This will tell the reader to read in any file in that path that starts with the .jp extension.
This will tell the reader to read in any file in that path that starts with the .jp extension. 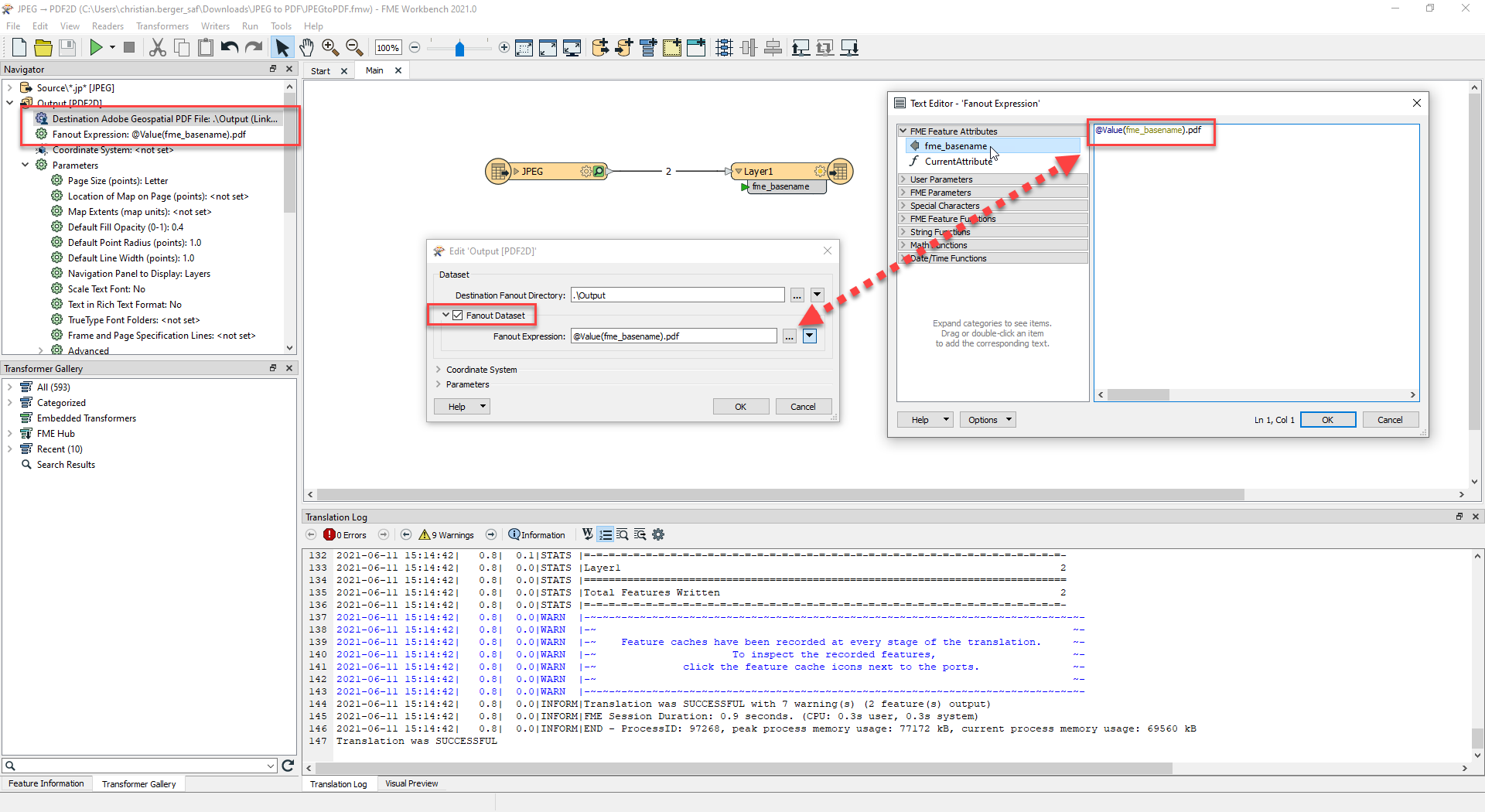 This will effectively tell the writer to create a new .pdf for every fme_basename attribute value.
This will effectively tell the writer to create a new .pdf for every fme_basename attribute value.