


The first dataset has 10500 objects ( a table with x,y id, date,etc. etc.)
The second dataset 7000 object s )(a table with x,y,id ,,date, adress etc.etc.)
Based on the x and y we would like to get a combined file as a result.
Where all 10,000 objects from the first dataset are located at the closest object to an address point.
A list of these..
It seemed logical to us to use the transformer neighbor finder for this. But this doesn't work.
ideas more than welcome
Johan



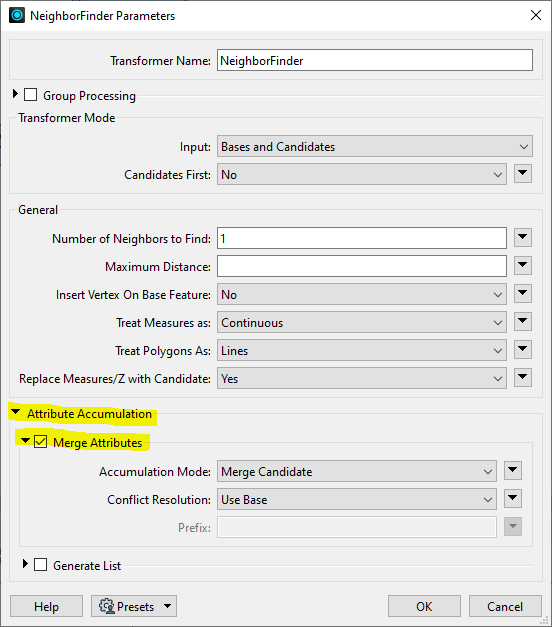
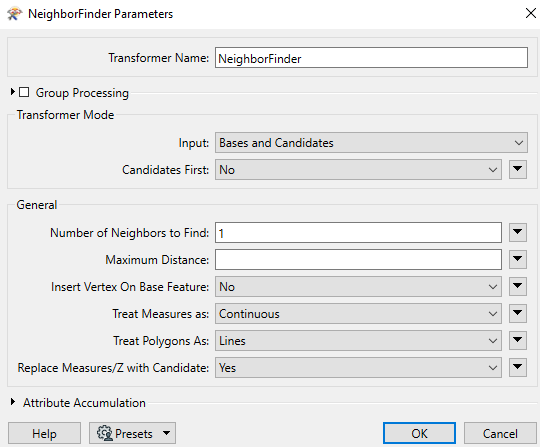 That's probably why I can't find it.
That's probably why I can't find it.