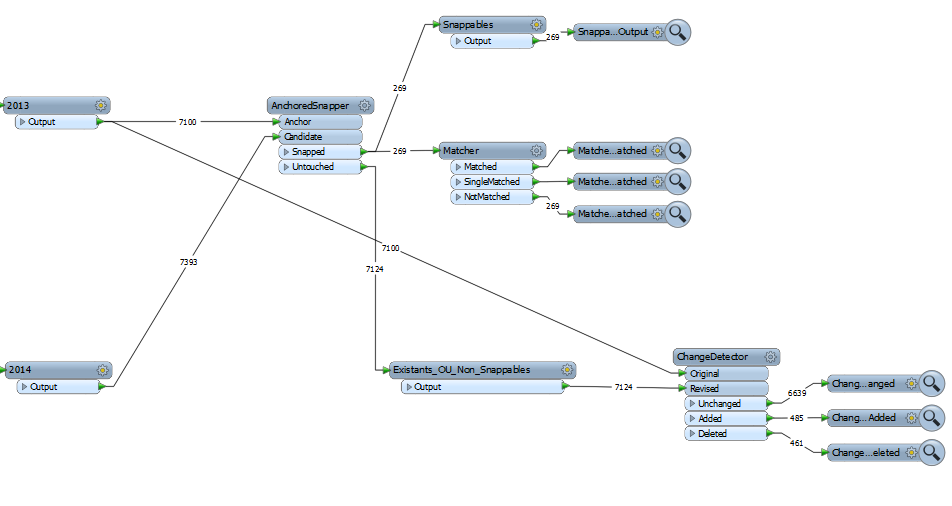
dans le cadre d'un processus de mise à jour je suis amené à comparer les modifications faites sur un ensemble de point entre deux moments donnés. J'utilise par conséquent un Transformer ChangeDetector pour obtenir les points n'ayant pas changés DU TOUT. Cependant il existe aussi des points bougeant PEU mais de manière suffisante pour que le ChangeDetector les considère comme différents. Pour palier à ca, existe-t-il un moyen d'integrer une tolérance de distance pour qu'un transformer ChangeDetector puisse faire passer dans le flux unchanged les points revised étant suffisament proche d'un original ?
Actuellement, j'utilise un NeighborFinder sur les flux Added et Deleted, pour creer ce mechanisme à la main, mais cette solution a trouvé sa limite lorsque deux points Base sont proche du meme Candidate, j'obtient alors des incohérences de résultat.