

Hi!
I have an issue with the Clipper-Transformer, that I would like to use for a batch deploy.
The clipper input is a Shapefile with about 1.7 Million polygons, defining a grid. The clippee are a few hundred Point Clouds as LAZ, that should be clipped according to the grid. I use batch deploy because otherwise the Point Clouds fill up the disk space and make FME crash.
The issue I have with batch deploy is, that the $hapefile (Clipper) is re-read everytime a new clippee is loaded, which is very time consuming.
Thanks a lot and with regards,
Matthias
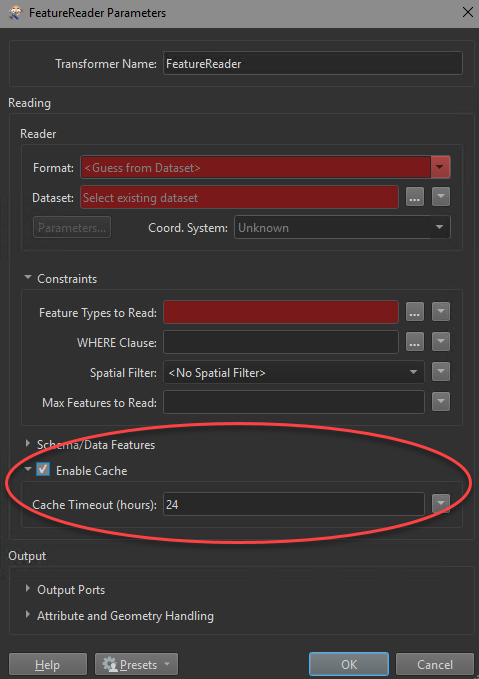 If the clipper feature data does not change frequently, set Cache Timeout to a high number of hours. The first time the workspace is run, the clipper features will be read from the source and cached. Subsequent runs within the configured timeout period will use the cache instead of re-reading the data from the source.
If the clipper feature data does not change frequently, set Cache Timeout to a high number of hours. The first time the workspace is run, the clipper features will be read from the source and cached. Subsequent runs within the configured timeout period will use the cache instead of re-reading the data from the source.

