


From this Q&A;: Extract data from webpage
Source HTML: https://historicengland.org.uk/listing/the-list/list-entry/1435084
I tested the HTMLExtractor in FME 2017.0.0.1 build 17271 to extract some parts from the source html setting a class name to the CSS Selector column.
Source HTML (part):
<div class="main-col">
<div class="text-col">
<h1>Basingstoke War Memorial</h1>
<h2>List Entry Summary</h2>
<p class="summary">
This building is listed under the Planning (Listed Buildings and Conservation Areas) Act 1990 as amended for its special architectural or historic interest.
</p>
<div class="attributeList">
<p><span>Name:</span> Basingstoke War Memorial</p>
<p><span>List entry Number:</span> 1435084</p>
</div>
HTMLExtractor Parameters:
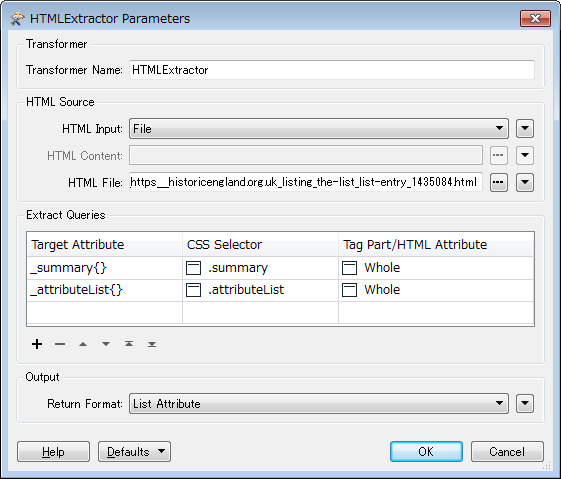
Result: Elements belonging to "summary" class have been extracted, "attributeList" class could not be extracted.
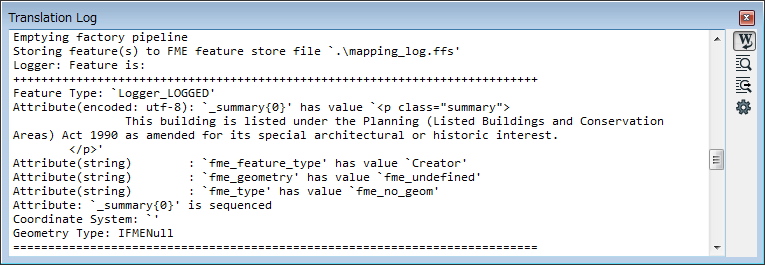
However, as mark_1spatial mentioned in the Q&A; thread, the HTMLExtractor could extract the div element if you replaced "attributeList" in the source with other string - e.g. "attributes".
Other than "attributeList" class, I found several settings in CSS Selector where the HTMLExtractor could not extract elements. Could you please investigate the reason why there are cases that the HTMLExtractor doesn't work as expected?