


Hi!
Hope someone can help me out with this:
I'm trying to create some sort of dynamic way to filter specific set of Attributes. Since the AttributeKeeper needs this input: AttributeName1,AttributeName2,AttributeName3,etc input, I was wandering if I can use a AttriubuteValue for this..but this is where I got lost;) I've created an attribute with concatenated list of Attributes I want to keep. But what would be a good approche to use this value to keep specific set of Attributes?
cheers,
ronald




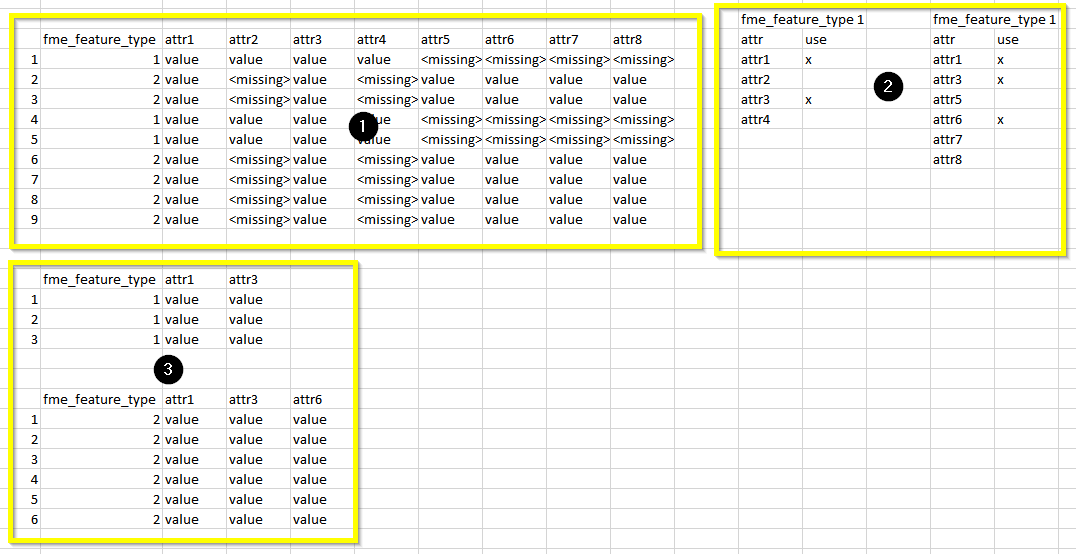 I have 2 input files: mdb (1) and xlsx (2).
I have 2 input files: mdb (1) and xlsx (2).
