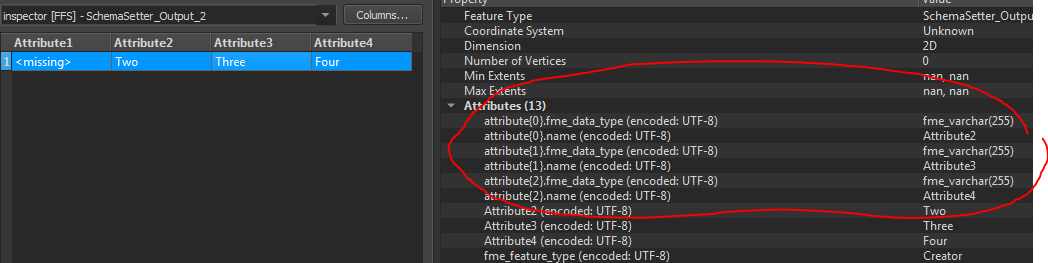
Hi. I was trying to figure out a way to rename all the fields of my output shape using a PythonCaller. I used the "BulkAttributeRenamer" to rename the fields, but just using a single parameter as: prefix, sufix, lowercase, uppercase etc and it's not enough. When I tried to use PythonCaller, I could change only the attributes itself, but not their field's name (I used the function setAttribute(name, new_value))
Is there a python function that can set the AttributteName ?





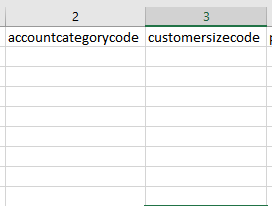 What I want to achieve is those attributes containing only missing value (like accountcategorycode and customersizecode in the photo) are not written to the Excel output. This is not achievable with feature.removeAttribute(name) as this function only makes all values under this attribute missing.
What I want to achieve is those attributes containing only missing value (like accountcategorycode and customersizecode in the photo) are not written to the Excel output. This is not achievable with feature.removeAttribute(name) as this function only makes all values under this attribute missing. 


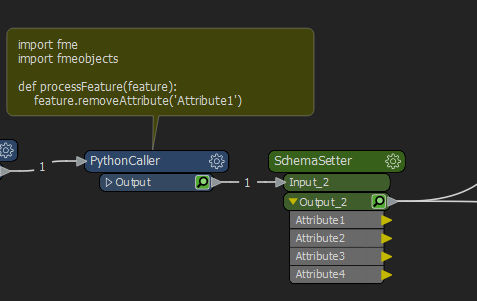 But if it's missing it won't be used to create the schema in the schemasetter
But if it's missing it won't be used to create the schema in the schemasetter