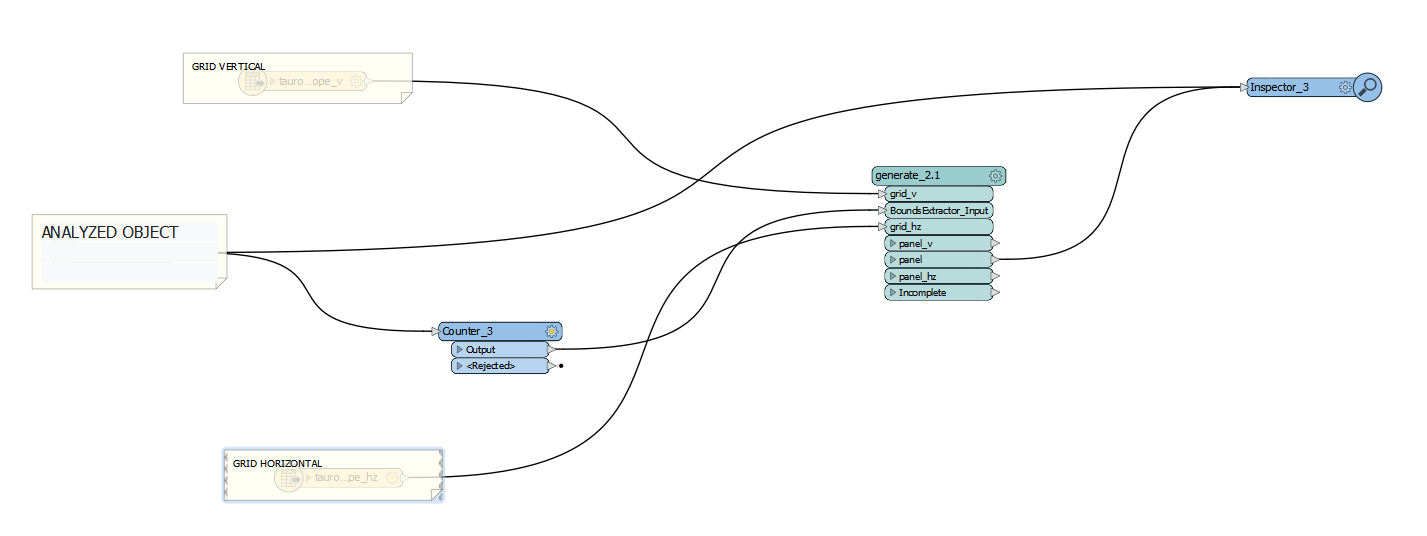
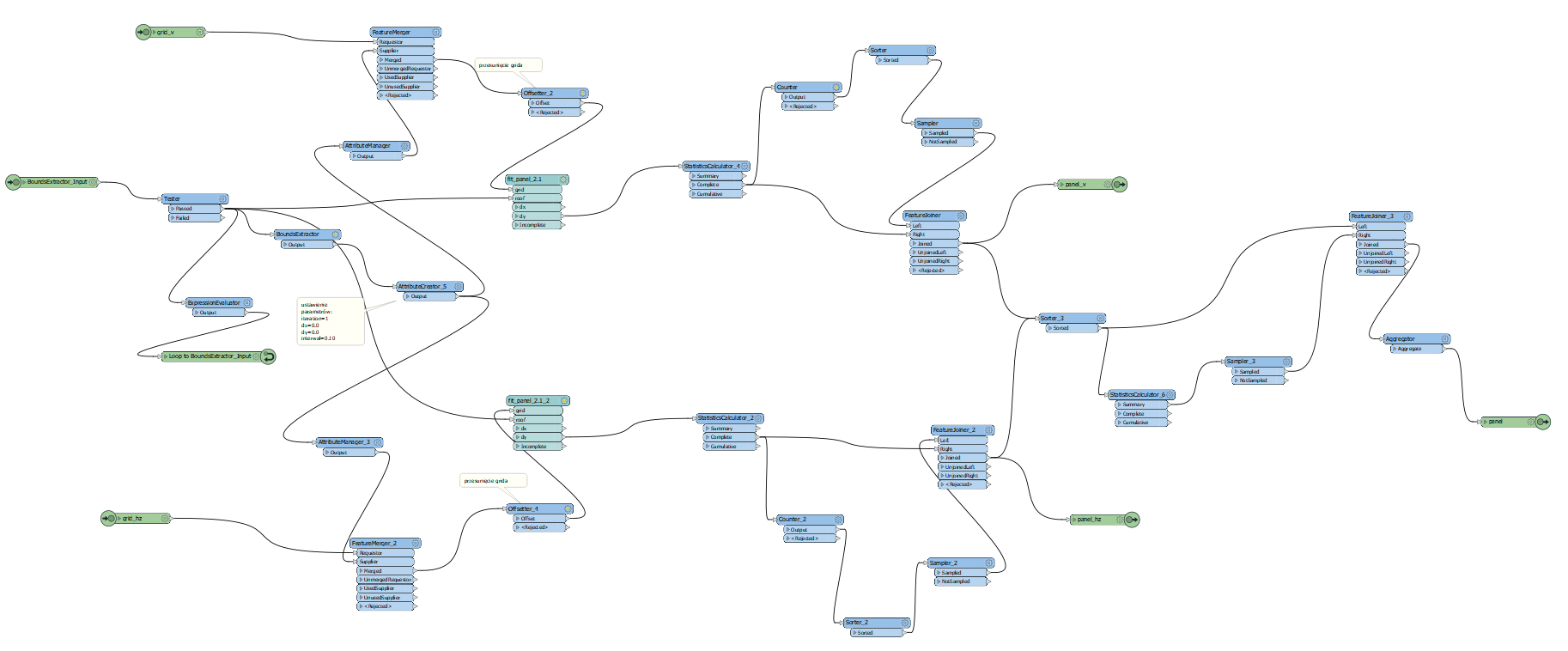
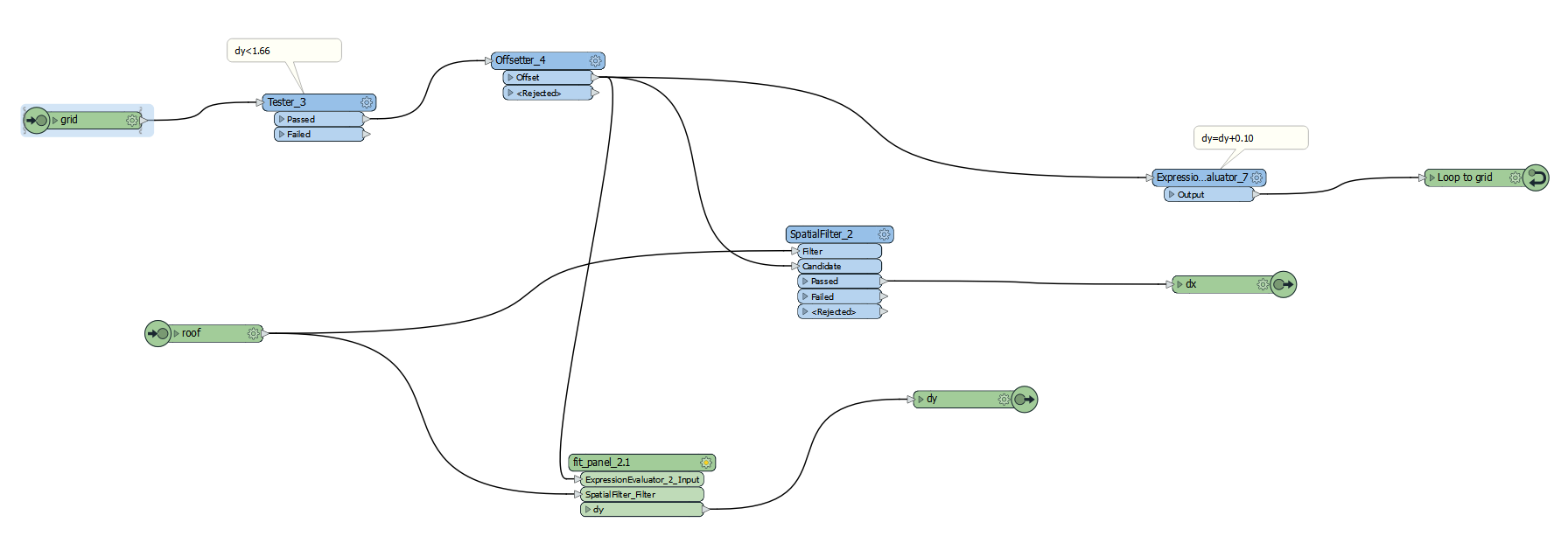
Hi,
I have to fit the maximum number of polygon with specified dimensions into another polygon.
I have to analyze two positions: vertical and horizontal and choose the most optimal placement (the largest number of polygons inside)
for example:
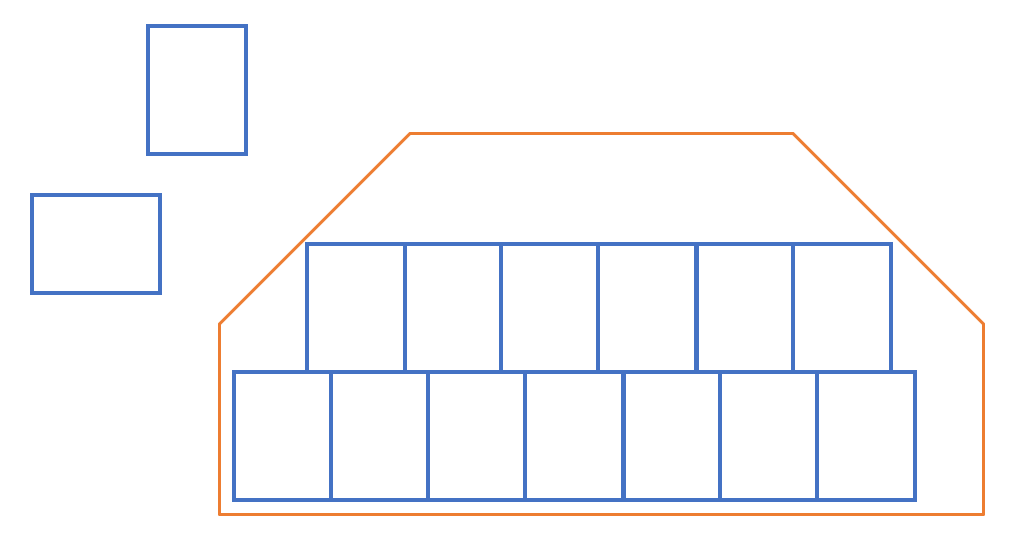
Do you have an idea how to do it in FME?