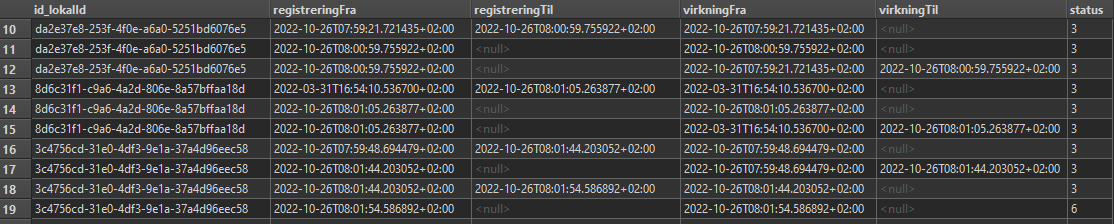
I have some date with id-blocks, meaning there is a column where one and the same object is represented of several features, with different attribute values, but always with the same id for these features.
How many features there are per object varies.
I was thinking to build some 'decision-tree' in an AttributeManager to find the correct features of such an id-block to process further. Unfortunately, the AttributeManager is not a group-by transformer and I was wondering how can I group my data by id, and process the resulting group, before the next group is created and processed.