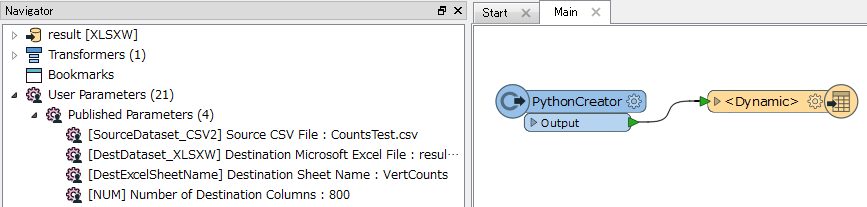
I use AttributeCreator to prepare a list of columns (A, B, C, D, etc..) for an Excel writer. My problem is that the list is 4000 items long. I have to manually expose every one of the column labels, which is not feasible. I have looked up and down and did not find a solution. Is there a way with PythonCaller to label a feature as exposed?

Solved
AttributeCreator and long list of attributes to expose
Best answer by takashi
In this case, replacing more transformers with Python codes could increase the performance drastically. For example:
# PythonCaller Script Example
import fmeobjects
# Get Excel Column Name (A,B,C,...) corresponding to a column index.
# index: 0-based column index
def xlsxColumnName(index):
alpha = ''
while 0 <= index:
alpha = chr(index % 26 + 65) + alpha
index = index // 26 - 1
return alpha
class FeatureProcessor(object):
def __init__(self):
self.column_index = 0
self.is_target = lambda attr: \
not '(1900/01/00)' in attr \
and not attr.startswith('fme_') \
and not attr.startswith('csv_')
def input(self, feature):
# Collect target attribute names.
attribs = [a for a in feature.getAllAttributeNames() if self.is_target(a)]
# First column (column index = 0) values are attribute names.
# Assume the first incoming feature has all target attributes.
if self.column_index == 0:
# Create and output a schema feature at first.
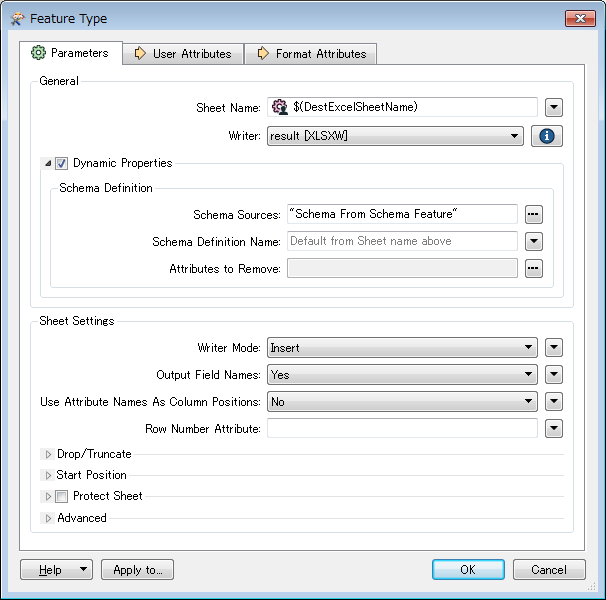
numColumns = int(FME_MacroValues['NUM'])
schema = fmeobjects.FMEFeature()
schema.setAttribute('fme_feature_type_name', \
FME_MacroValues['DestExcelSheetName'])
schema.setAttribute('fme_schema_handling', 'schema_only')
for i in range(numColumns):
schema.setAttribute('attribute{%d}.name' % i, xlsxColumnName(i))
schema.setAttribute('attribute{%d}.fme_data_type' % i, 'fme_real64')
self.pyoutput(schema)
item = fmeobjects.FMEFeature()
for attr in attribs:
item.setAttribute('_attr_name', attr)
item.setAttribute('A', attr)
self.pyoutput(item)
self.column_index = 1
# Explode the incoming feature with the target attributes.
item = fmeobjects.FMEFeature()
columnName = xlsxColumnName(self.column_index)
for attr in attribs:
item.setAttribute('_attr_name', attr)
item.setAttribute(columnName, feature.getAttribute(attr))
self.pyoutput(item)
self.column_index += 1
There still is a room to improve the performance.
To be continued (maybe).
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.