


Hello Everyone,
I have several readers & writers, I want to restrict the attributes of shape file based on excel file (other reader).
Eg: I have shape file with 25 attributes, out of which I may require 10 attributes for translation. As of now I'm using attributekeeper after reader to restrict the attributes which are not required.
For further explanation, whatever the attribute names I pass through the excel file only those attributes have to be passed from shape file.
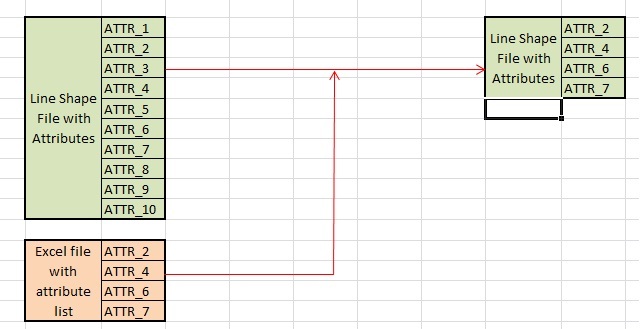
Note: Excel file contains only attribute headers
Is there a way to perform this???
Thank you



