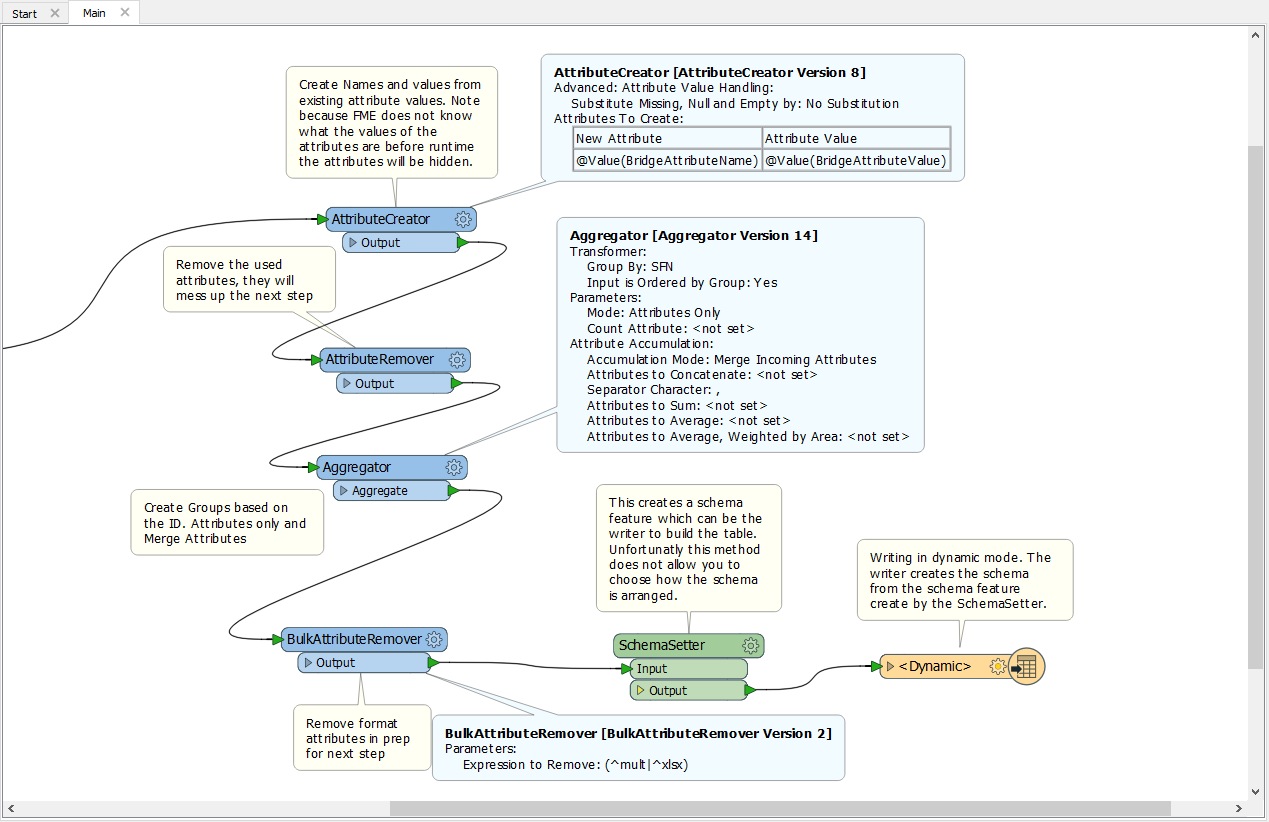
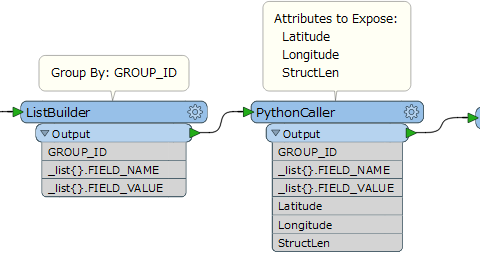
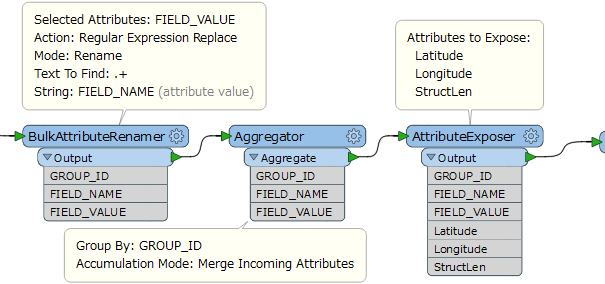
I have a table of non-spatial features. Each row has a non-primary key that it shares with 39 other rows. Each row contains a unique attribute type. For example: Row 1= "10 County"; Row 2 = "10 State"; Row 3 = "10 District" .... Row 41 = "20 County", Row 42 = "20 State" .... etc. How can I pull all the "10" attributes "20" attributes into single rows, each containing the 40 attributes?

Question
Aggregating Multiple Rows
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.