Hi!
I am kind of new to FME so this must be a simple issue to solve for anyone in here.
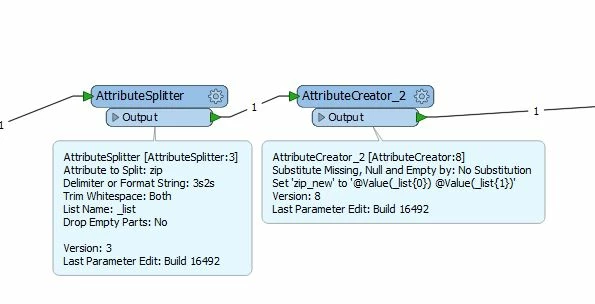
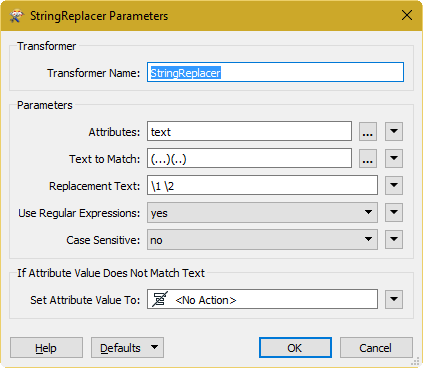
I have a xls-file with zip codes, 5 characters together. I want to add a blank space between the third and the fourth character. I just can´t find a simple way to do it with my limited knowledge...
Thanks,
Tobias