Hello,
I have 4 excel documents hosted on SharePoint, I am using a FeatureReader taking in a temp download path.
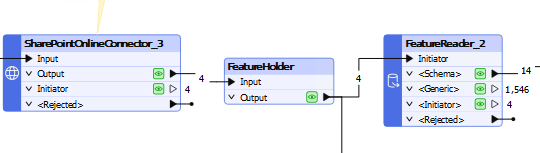
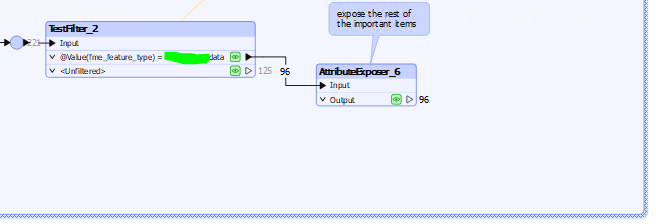
As can be seen the 4 items are being opened successfully in the featurereader, but the data is not grouped in any meaningful way for me to extract and sort out the various excel documents data (which is varying formatting, some have multiple tabs with differing data/headers between them, as you can see there are 14 schemas (total tabs within excel docs), and 1546 generic bits of data (total rows))
I’ve read that I can re-group the datasets by using fme_basename but I cannot work out how to expose this, I’ve found the post below, which offers suggestions of how to expose that data. But the solution it offers is not applicable, I am using version
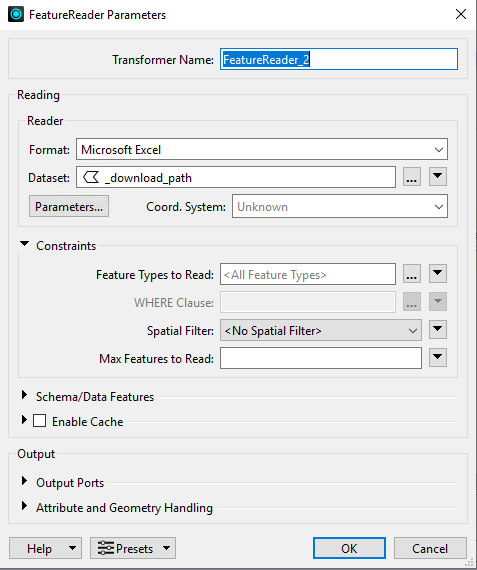
Does anyone know how I can expose the fme_basename?
OR
Is there a better way to do this?